パネルディスカッション「生命科学の未来を予想する――データベースはもう要らなくなる...ってコト?!」(前編:話題提供1・牛久氏/二階堂氏)

ChatGPTをはじめとした生成AIは、データの取り扱いに関して従来困難と考えられてきた様々な課題を解決しうると期待されています。また、ロボット技術を用いたラボラトリー・オートメーションの進展は、均質で大量なデータの迅速な取得を可能にしつつあります。今後、生命科学はどのように変わってくでしょうか?
「トーゴーの日シンポジウム2024」(2024年10月5日・品川) のパネルディスカッション「生命科学の未来を予想する――データベースはもう要らなくなる...ってコト?!」では、6名の専門家が生命科学における研究プロセスや人間の研究者の価値の変化や不変性、AIとデータベースとの関係、教育方法や求められるスキルの変化などについて広範囲に渡って話し合われました。
本パネルディスカッションの投影スライドや動画は、下記ページからご覧いただけます。

NBDCブログでは、本パネルディスカッションの議論の内容を3編 (前編:話題提供1(牛久氏/二階堂氏)・中編:話題提供2(森氏/大上氏/大田氏)・後編:議論) に渡ってお届けします。本記事はその前編で、高木氏からの趣旨説明および牛久氏、二階堂氏からの話題提供をご紹介します。
牛久氏は「AIロボット駆動科学」と題し、オムロンサイニックエックス株式会社(OSX)が実施する、AIとロボティクスによって科学研究プロセスを自動化・加速するためのプロジェクトとその成果を紹介しました。
また、二階堂氏は「基盤モデル時代のオミクス研究とデータベース」と題し、オミクス研究における基盤モデルの重要性について述べ、そうした基盤モデルを開発するために広範なデータ取得が重要だと強調しました。
趣旨説明 (NBDCライフサイエンスデータベース特別主監・高木 利久)
高木:これから「生命科学の未来を予想する」というタイトルのパネルディスカッションを始めます。私のような、人生に未来がない人間が生命科学の未来を論じてもという向きもあろうかと思いますが、逆に気楽でいいということで司会をつとめます。どうぞ、よろしくお願いいたします。

高木:今回のトーゴーの日シンポジウムのテーマ「AI+ロボティクス+データベースが変える生命科学」を受け、このパネルディスカッションでは、生命科学の未来がどうなるのかについてディスカッションします。
最初に5人のパネリストから1人5分ずつ話題提供いただいたうえで、前半では生命科学の未来、なかでもバイオインフォマティクスの未来を議論し、後半ではデータベースに焦点を当て、データベースの未来やあるべき姿を議論します。時間配分は前半7-8割、後半2-3割程度と考えています。
できるだけ過激にやった方が面白いと考えておりますので、少々気分を害される人がいるかもしれませんが、お許しください。また、議論がまとまらないこともあろうかと思います。「データベースは大事だね」というまとめ方はしません。ひょっとすると「データベースがいらない」という話になることもあるかもしれません。それでは困るのですが、それはそれで仕方がないと思っております。

高木:前半部に関連し、簡単に私なりにどのように考えているかをお話ししますと、生命科学の研究プロセスのどこがどう変わるのか。あるいは研究プロセス自体が大きく変わるということもあろうかと思います。また、データベースはどのように貢献することが期待されているのか。そうした時代にあって研究者の仕事はどう変わるのか、もっと言うと失業してしまうのか。これからの研究者に求められる専門性は何か。それから、バイオインフマティクスは非常に大事だと言われておりますし、人材も非常にニーズが高いわけですが、今後要らなくなるのか、どんな仕事になるのか。そういうことを踏まえ、未来に向けてどんなことを解決していかないといけないのか、といった点をお話できればと思っています。

高木:後半は、データベースAI、データベースとロボティクスが、それぞれ今どういう関係にあって、今後どう変わっていくのか。また、データベースに求められるものは今後どうなっていくのか。データベース利用者は人間を前提としていますが、これからはAI、ロボットになるのか。データベースを誰が開発・提供していくことになるのか。バイオインフォマティシャンなのかアノテーターなのか、それともAIが作ってくれるのか。実験ロボットが取得したデータをそのまま流し込めばデータベースができるのか。もし、データベースが今後も重要なのだとしても、それはデータの量を確保するためなのか、データの質を担保するためなのか、あるいは統合された知識が求められるのか。繰り返しになりますが、1次データベース、2次データベース、統合データベースのあり方とは。今後データベースに何が求められ、そのためにこれからどういう技術を開発していかないといけないのか。こうした問いが頭の中を巡っていて、本日議論できればと思っています。また、これらに限らない論点も出てくるだろうと期待しています。どうぞ、よろしくお願いいたします。
高木:それでは、まず牛久先生、お願いします。
話題提供1:AIロボット駆動科学(オムロンサイニックエックス株式会社・牛久祥孝)

牛久:オムロンサイニックエックス株式会社の牛久祥孝でございます。AIロボット駆動科学におけるOSXの挑戦というタイトルで話題提供させていただきます。
なぜ私がトップバッターになっているかというと、多分、このトーゴーの日シンポジウムに1番関係のない人間だからでございます。

牛久:私自身は、スライド右上にあるように、画像、このセンシング・データから人の言葉、テキストに変換するAIの研究に10年以上取り組んでいます。場合によっては、逆にテキストからこういったビジュアルなデータに変換することもあります。このような、いわゆるビジョン&ランゲージと呼ばれる研究をAIの分野でやってきました。

牛久:もう1つご紹介しないといけないのが会社名でございまして、何しろ「オムロンサイニックエックスの牛久です」と言った後に「あ、オムロン...サニッ...クスの...牛久さん、なんですね?」みたいな感じになるので、会社の紹介もさせてください。
オムロンは血圧計などで有名な会社だと自負しているのですが、その研究所、子会社でございます。主に、ロボティクスであるとかAIであるとか、ヒューマン・コンピューター・インタラクションといった研究をしておりまして、東京にあります。オムロンは京都の会社なのですが、我々は東京で、20人ぐらいしかいない、こぢんまりとした研究所でございまして、親元の目を離れてのびのびと研究をしております。略してOSX(オー・エス・エックス)と呼んでいます。
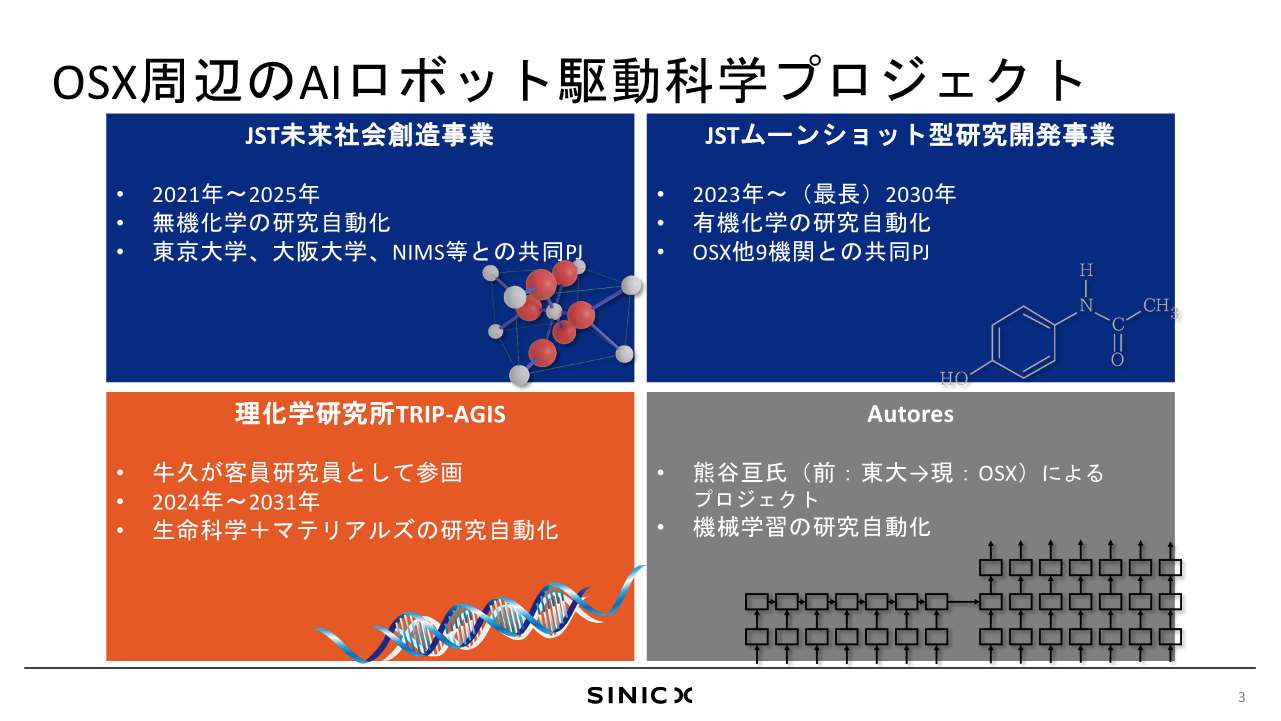
牛久:OSXでは、AIやロボットによって科学の研究プロセスを加速する・自律化するというプロジェクトを複数走らせています。
例えば、JST未来社会創造事業において――本シンポジウムの午前中、高橋 恒一先生が講演されましたが――別のプロジェクトとして東京大学の長藤 圭介先生を中心として無機化学を加速する研究プロジェクトに取り組んでおります。
また、JSTムーンショット型研究開発事業では、私がプロジェクト・マネージャーを務めて有機化学のAIロボット駆動を進めております。
また、高橋先生や二階堂先生も参画されているTRIP-AGISが理化学研究所で始まっておりますが、こちらに客員研究員として私や数名の研究員が参加しており、生命科学やマテリアルズの研究の自動化・加速を目指していきたいと思っております。
さらに、オムロンサイニックエックスに在籍している熊谷という機械学習の研究者がいるのですが、機械学習によって機械学習の研究を加速する――そう、Sakana AIにAI Scientist論文を先行して発表されて「ぐぬぬ」と悔しがっている人などが弊社におるわけでございます。
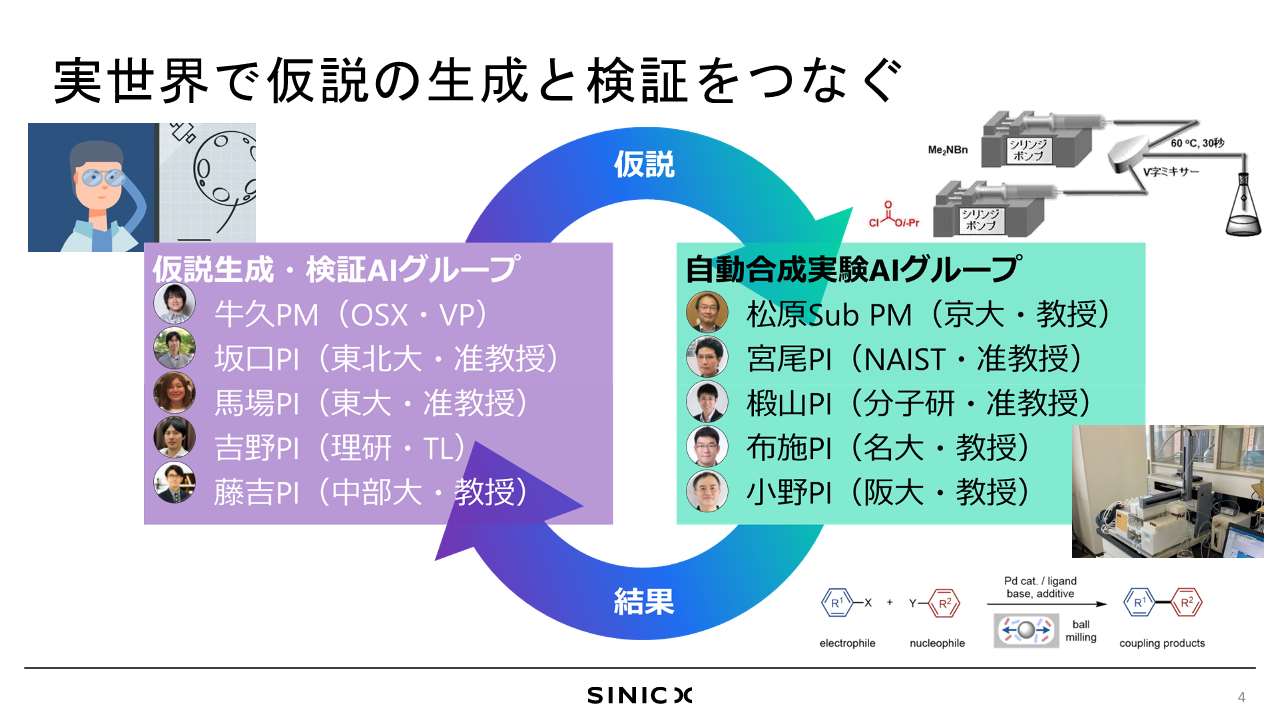
牛久:ムーンショット事業における研究プロジェクトの説明をさせていただくと、実世界で仮説を生成するAIのグループと自動実験するグループとでぐるぐるループを回していこうと思っております。
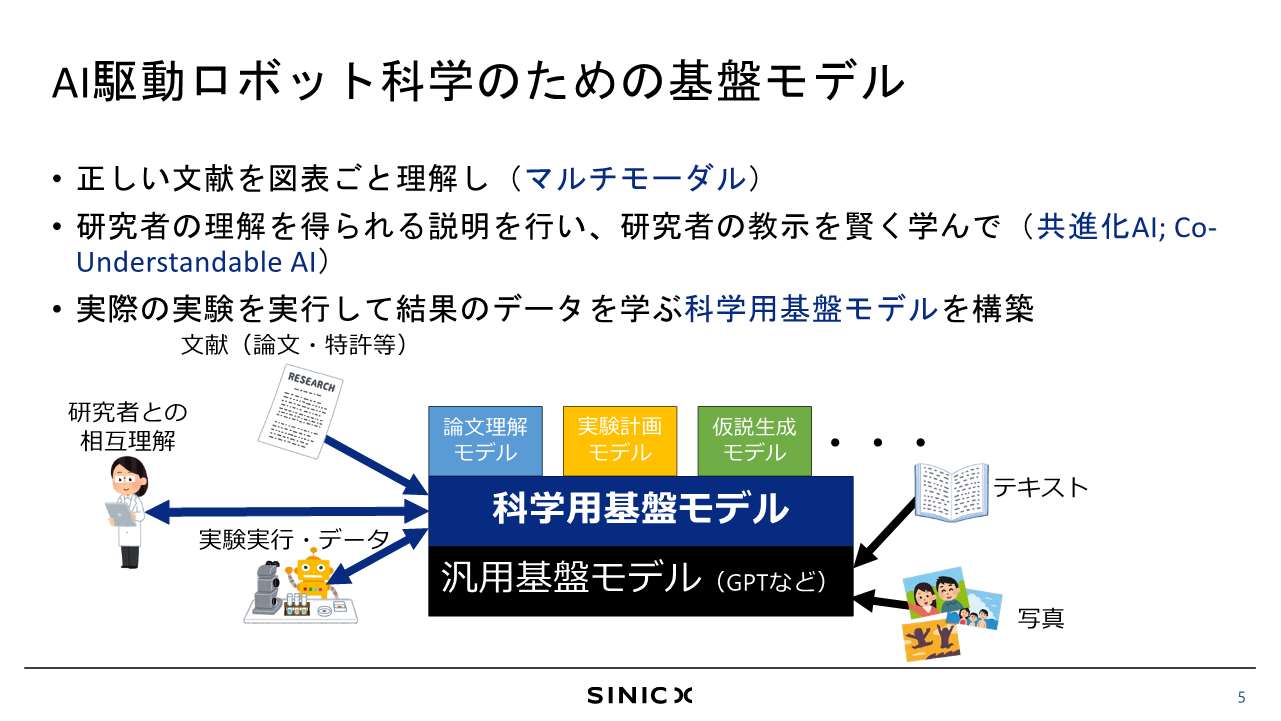
牛久:GPTなどの基盤モデルを活用するだけではなく、自律駆動の実験そして科学の発展のためにアップデートしていこうと考えています。

牛久:最近の研究成果をかいつまんでお話しすると、例えば、人の言葉でロボットに指示を与えてその通りに動かすロボットですとか、その応用先として実際にサブ・ミリグラム精度で試料を測りとって混ぜるロボットの研究があります。
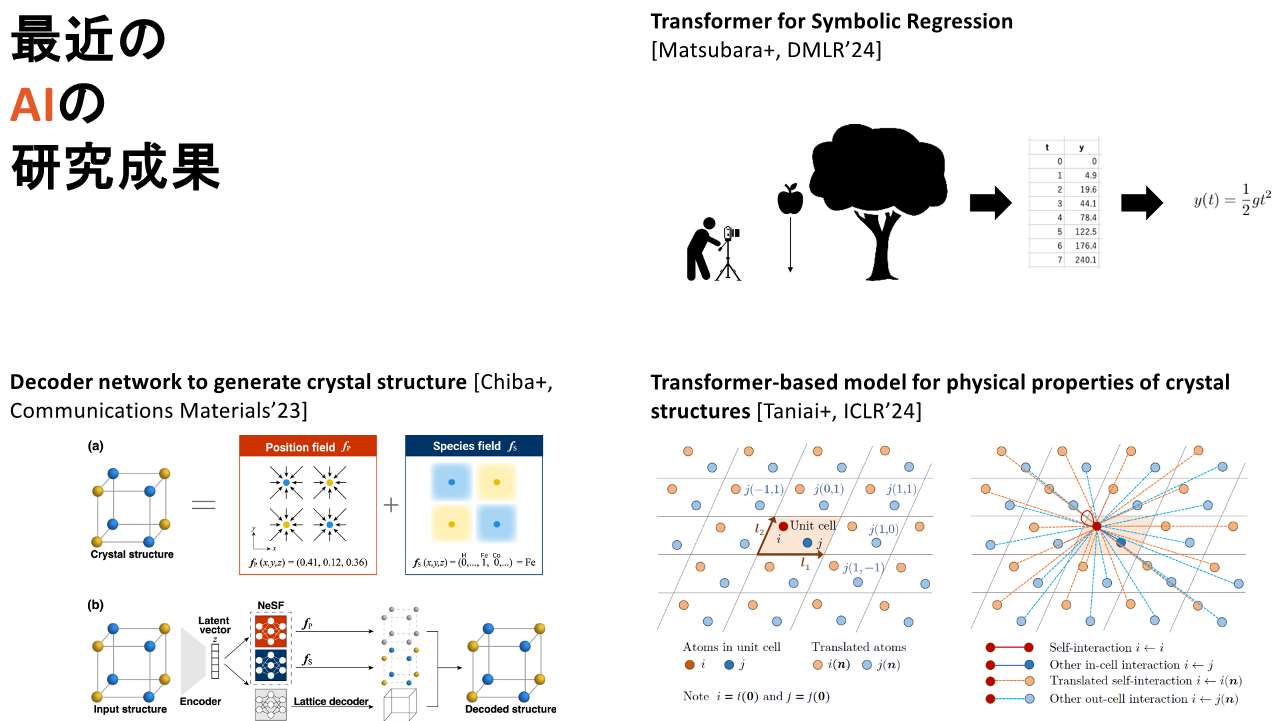
牛久:また、よく「AIでアイザック・ニュートンを再現するんです」と言っているのですが、リンゴの木からリンゴが落ちる様子を見て「y=(1/2)gt2」という数式を思いついたニュートンの代わりに、時刻Tとリンゴの高さYのテーブルデータを与えて「y=(1/2)gt2」をAIが出力できるかといった研究や、無機化学において結晶構造の生成であったり、結晶構造を与えられた時に物性を推定したりする研究などを行っております。
牛久:最後に、いくつか宣伝させてください。午前いらっしゃっていた方はもうすでに聞かれたかと思いますが、2024年10月28日に東京大学でAIロボット駆動学研究会を行います。高橋さんも私もそして他にムーンショットやJST未来ほかで代表されている方々共同で開催します。ご興味ある方はご参加ください。
また、オムロンと理研ではリサーチャーを絶賛募集中です。ご興味ある方はお越しください。
あと、ムーンショットのスピンアウトとして今月起業したばかりなので、ベンチャーに興味ある、AIロボット駆動科学でのビジネスに興味ある方は是非お越しください。以上です。
話題提供2:基盤モデル時代のオミクス研究とデータベース(理化学研究所/東京科学大学・二階堂 愛)

二階堂:こんにちは、二階堂です。私はオミックス研究に取り組む研究者でバイオインフォマティクス専門なのですが、ラボとしてはDNAシーケンサーを使った実験技術の開発にも取り組んでいます。オミクス研究分野においてどういうAIの研究が進んでるかについて現在地を確認し、私がどういう方向に向かおうとしてるのかをお話ししようと思います。
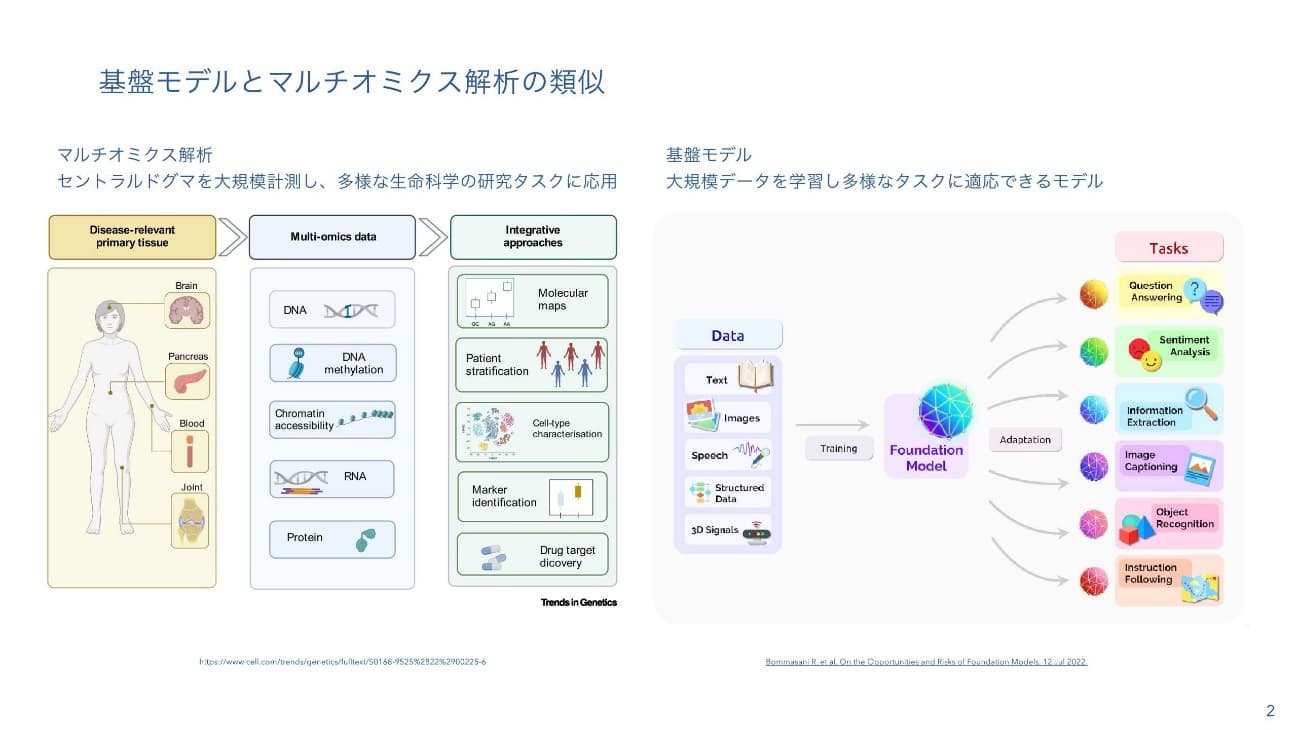
二階堂:基盤モデルはゲノミクスとすごく相性がいいと思っています。現代のゲノミクス研究では、1つの検体をマルチオミクス解析し、データを統合して、薬を作ったり、診断のマーカーを取ったりといった様々なタスクに利用しようとしています。一方、基盤モデルは、大規模なデータを、大規模なパラメーターを持つAIで学習させることによっていろんなタスクがこなせるもの。このスライドの右と左がそっくりだと僕は思っています。バイオインフォマティクスには、マルチオミクス・データをある1つのAIに聞いて何でもやってくれるという期待が寄せられていると感じています。ですから、基盤モデルは必ずゲノミクスで使われていくことになると思っています。
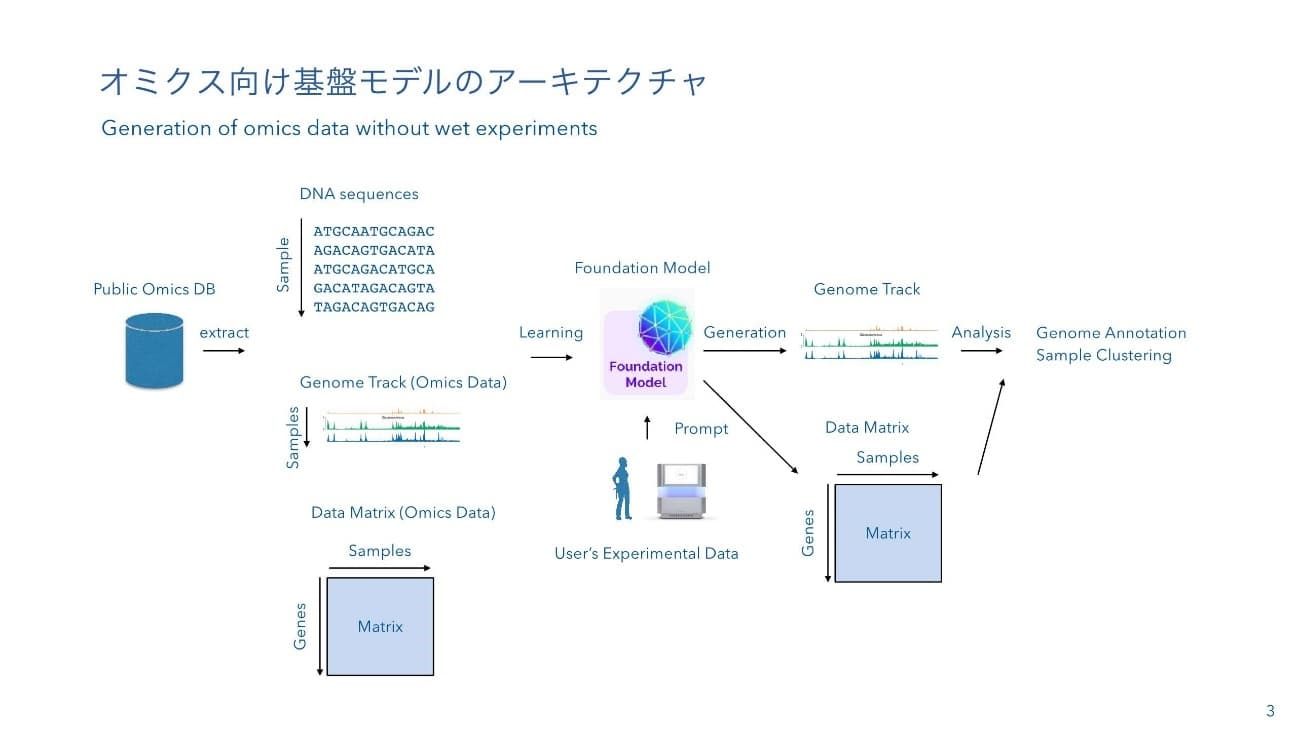
二階堂:これまでにいくつかの基盤モデルが出てきていますが、どういうアーキテクチャーしているでしょうか。ゲノミクス分野ではデータをどんどん公開してきました。この会場にいる皆さんも色々なデータベースを作ってるわけです。様々なゲノムの配列自体、ゲノムの座標のどこにどういうものがあるかを示す、ChIP-seq、RNA-seqのようなトラック・データあるいはRNA-seqの行列データなどのデータがインターネット上で数多く公開されているので、これをAIにとにかく覚えさせます。ユーザーがそのAIに聞くと、トラック・データや行列データを手に入れることができるので、こうした公開データを自分で計測したと仮定させ、いろいろな解析をさせるモデルがいくつか登場しています。
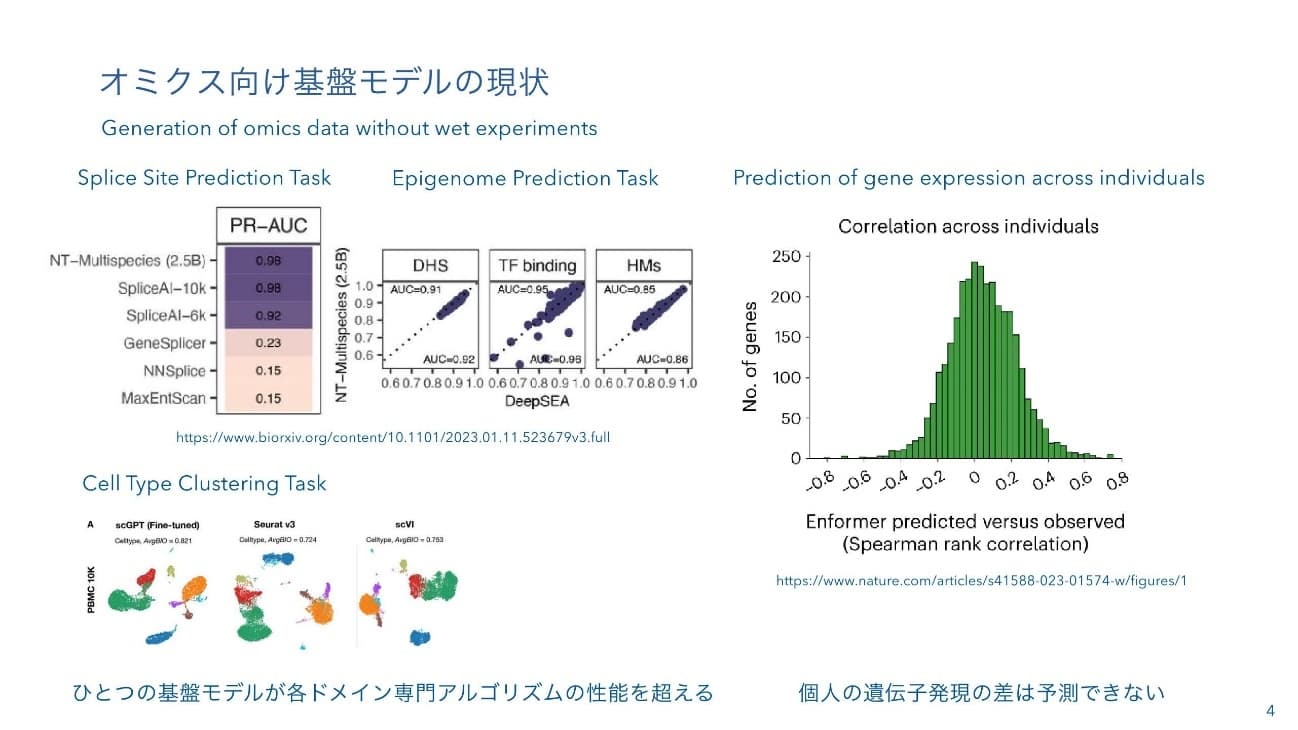
二階堂:このAI一つでいろんなタスクをこなせることが示されています。例えば、Splice Siteの予測タスクにおいては、バイオインフォマティクスの専門ツールを超える性能が出ています。エピジェネティクスやシングルセルのセルタイピング、クラスタリングのタスクでも、他の専門ソフトウェアの性能を上回っており、個別のバイオインフォマティクスのアルゴリズム研究が、今後、意味がなくなってくる可能性があるのではないかという大きな危機感を覚えるところです。
一方で、例えば、スライド右側に示す nature geneticsの論文では、個々人の遺伝子発現の差を基盤モデルで予測できるかを調べたものですが、実測値と予測値の相関係数が0で、ほぼ予測できていません。
基盤モデルの性能は良さそうなのですが、しかし、まだ実務的に使えるレベルではないかもしれません。
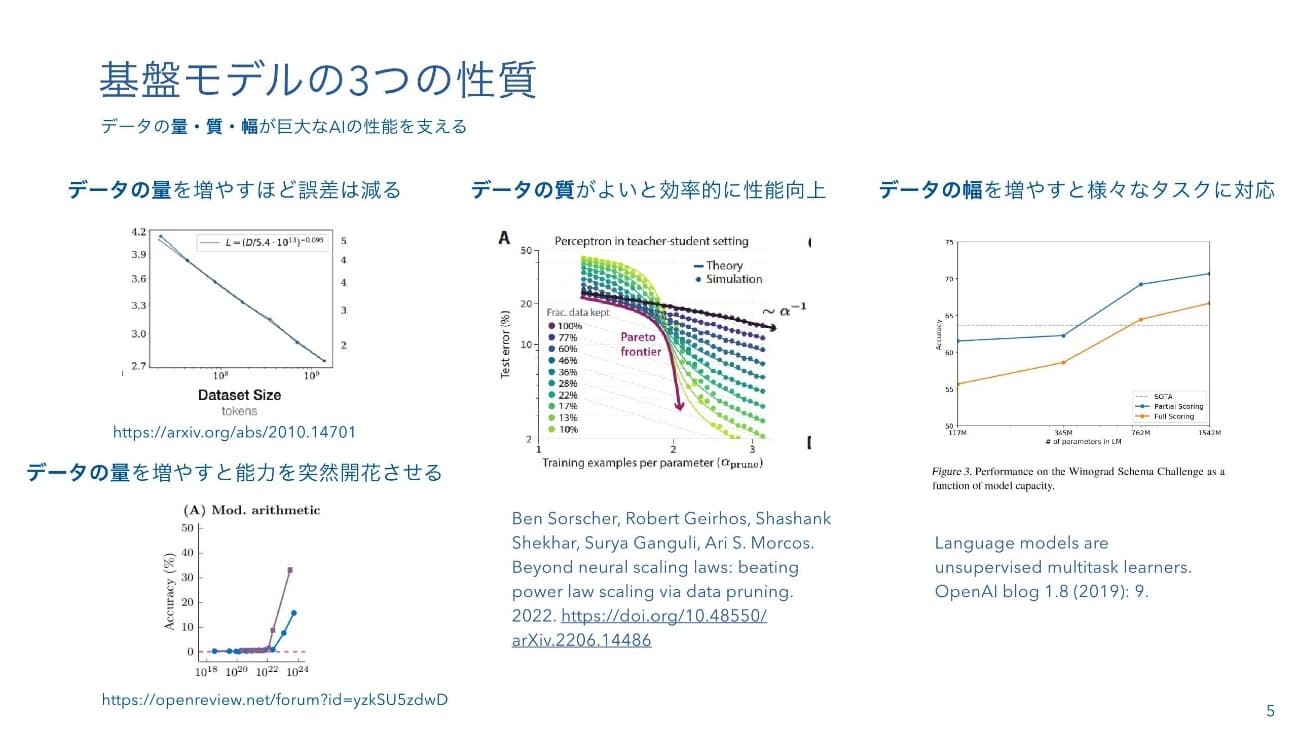
二階堂:基盤モデルが「やばい」と言われる理由は次のような性質を持つためです。まず、たくさんの「量」のデータを与えると性能がどんどん上がっていき、それまで全然できなかったタスクが急にできるようになります。また、与えるデータの「質」を高めると、単に量を増やすよりも早い速度で賢くなります。さらに、この図はGPT2の論文から引用したものですが、「幅」の広いデータを学習させると様々な常識を獲得し、新しいタスクに対応できるようになります。
こうした性質を踏まえると、とにかくたくさんのデータを所有していて、データを取得するための資金を持っていて、計算できるGPUを持ってる人が勝つという世界になりかねない状態です。
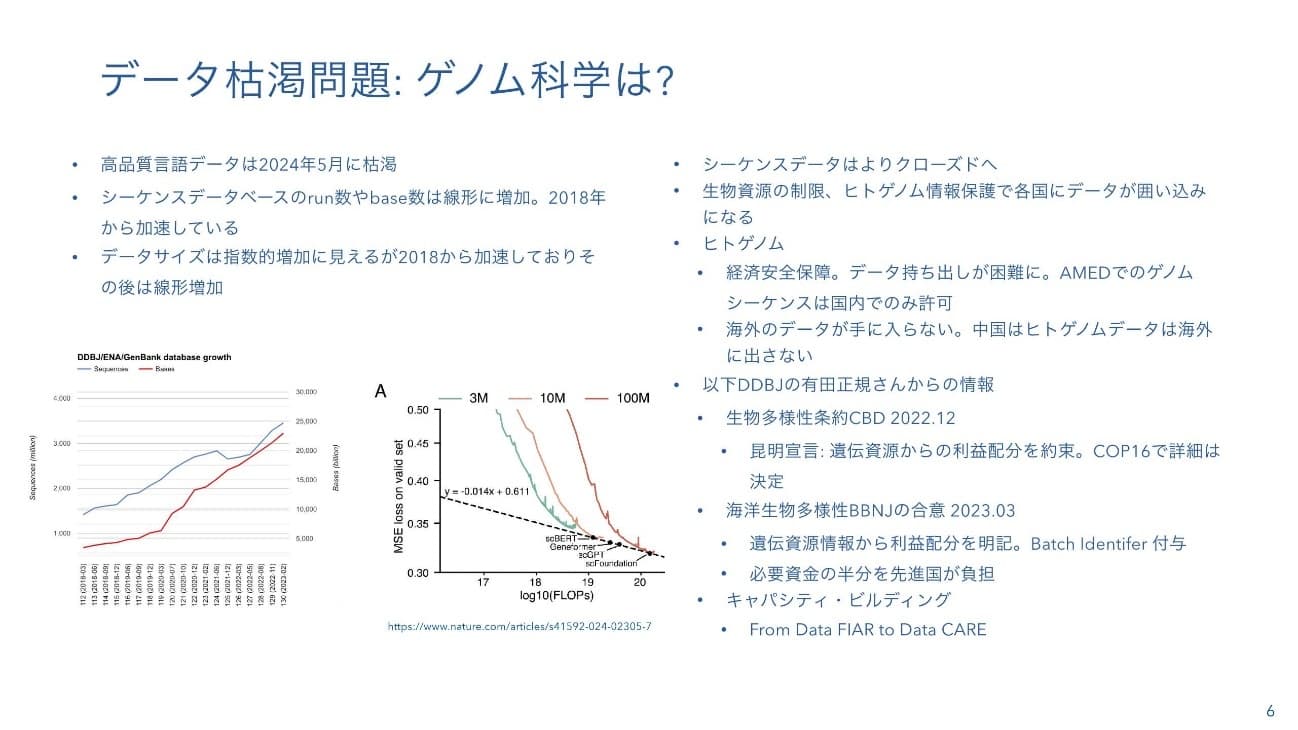
二階堂:さらに、言語データに関しては、枯渇すると言われてきています。論文やソースコードのような高品質の言語データは、もはや人間が生成するよりもAIが学習する速度の方が速い状況です。ゲノムシーケンサーは、最近、性能が伸びず、一時期はデータ量が指数的に増えていたのが今は線形増加になっているように見えます。スケーリング則に関しては、実際、データを増やしてくと性能が良くなっているように見えます。
また、非常に偏った遺伝子でしか研究がなされてない問題や、経済安全保障の観点や色々な情報を誰が活用するのかということに関してデータをクローズにしていこうという流れがあります。
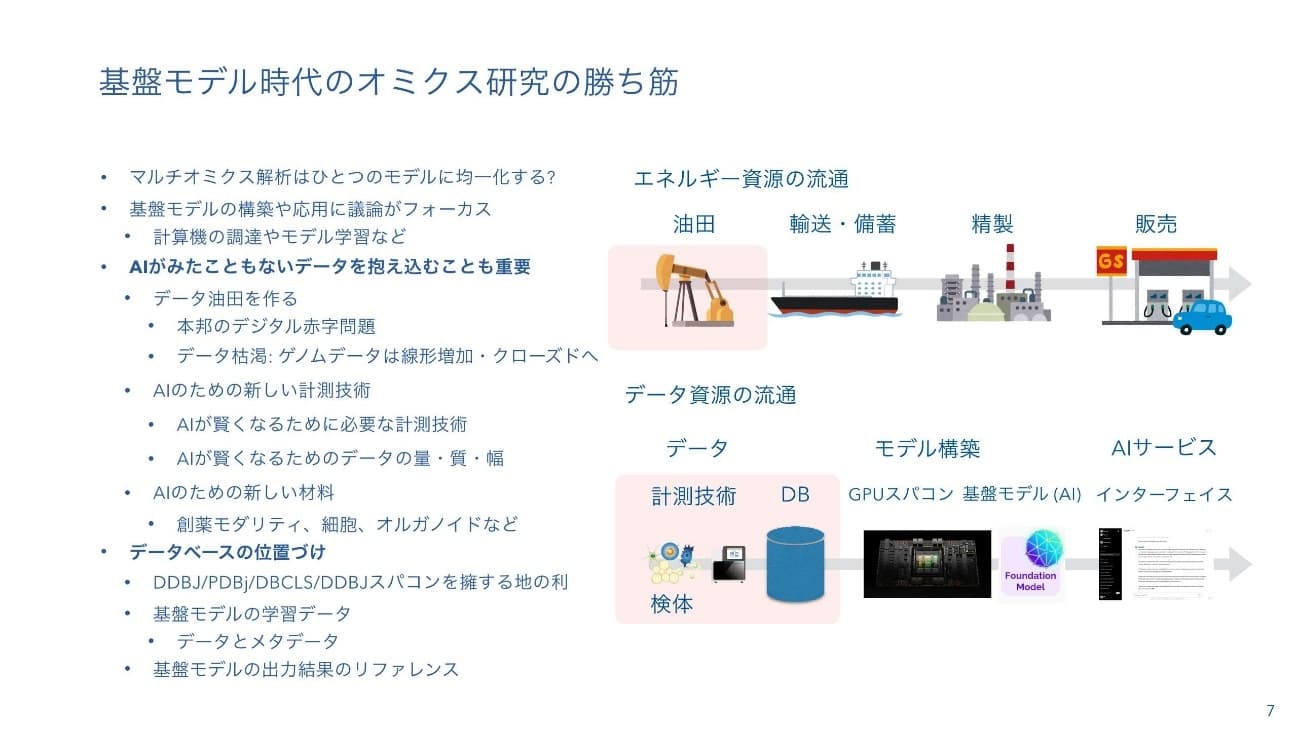
二階堂:このような状況を踏まえ、データをたくさん所有することが重要になってきています。GPUをどうやって買うかに注目が集まりがちですが、AIが見たことないデータをどんどん集めていく必要があって、たくさんのデータを計測し、データベースとして整備してAIに見せられる状態に格納することが、今後のライフサイエンスあるいはデータベース研究にとって非常に重要ではないかと考えています。
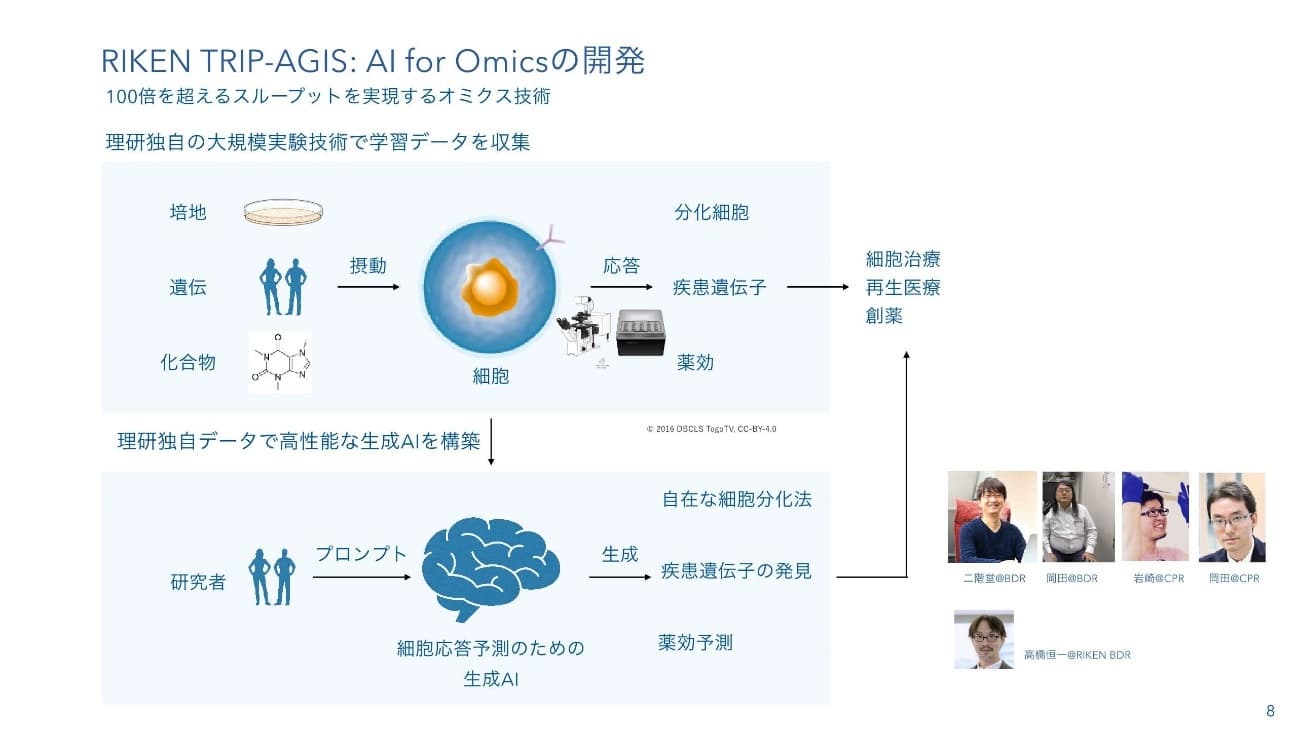
二階堂:このようなことから、理化学研究所では公共のデータベースの100倍を超えるぐらいのデータを集めてAIを賢くしていこうというプロジェクトを始めているところです。
前編は以上です。
中編では遺伝研の森先生、Science Tokyoの大上先生、千葉大学の大田先生からの話題提供、後編では議論の内容をお届けします。
