パネルディスカッション「生命科学の未来を予想する――データベースはもう要らなくなる...ってコト?!」(中編:話題提供2・森氏/大上氏/大田氏)

前編:話題提供1(牛久氏/二階堂氏)に引き続き、「トーゴーの日シンポジウム2024」(2024年10月5日・品川) のパネルディスカッション「生命科学の未来を予想する――データベースはもう要らなくなる...ってコト?!」の内容をお届けします。
森氏は「マイクロバイオームのDB開発における既存知識の抽出・整理のためのLLM活用」と題し、「Microbiome Datahub」の構築や自然言語処理を用いた論文からの情報抽出ツールの開発について紹介したうえで、データベースの将来的なあり方について問題提起しました。
大上氏は「AIでなんでも解決できるのか?」と題し、AI、情報科学でできること・できないことをAlphaFoldなどの具体例に基づいて紹介したうえで、そのような「できる・できない」の見極めや、情報科学等の基盤分野からの技術の「輸入」、生命科学等の応用分野における「かゆいところ」をいかに解消するかを考えていく重要性を強調しました。
大田氏は「生成AIは生命科学の何を変えるのか」と題し、生成AIには解決すべき多くの問題があること、なかでも研究応用には正確さの担保が不可欠であることを述べ、データベースが担う役割を論じました。また、自律的に研究プロセスに取り組むことのできる「つよつよAI研究者」が出現した後も人間はサイエンスする意味があるのかについて議論すべきだと言及しました。
なお、本パネルディスカッションの投影スライドや動画は、下記ページに掲載しています。
話題提供3:マイクロバイオームのDB開発における既存知識の抽出・整理のためのLLM活用(国立遺伝学研究所・森 宙史)

森:遺伝研の森です。よろしくお願いします。私は、主に、データベース開発者の視点から話題提供したいと考えております。

森:私は、微生物、特に原核生物のゲノム解析やいろんな環境のゲノム解析――非常に雑多な配列データが出てくるデータから様々な微生物の機能や系統等を推定する技術ですが――の情報解析および一部実験をおこなっています。基本的にはバイオインフォマティシャンです。
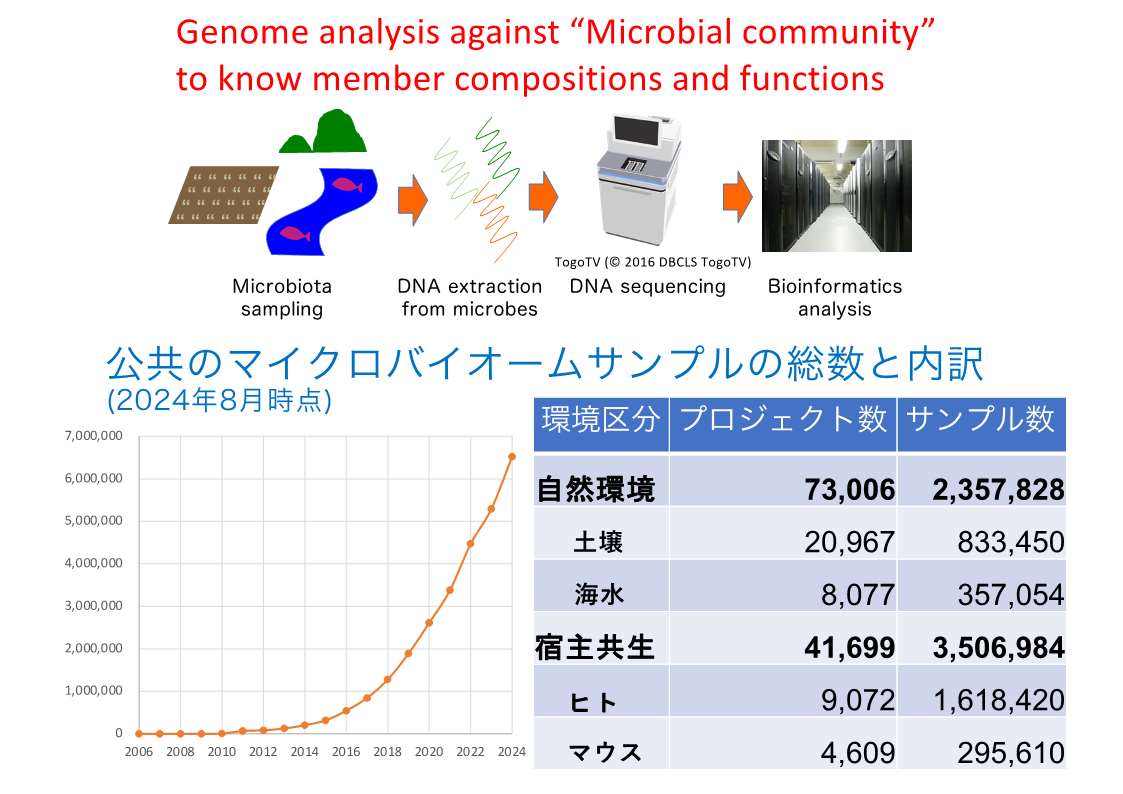
森:現代のメタゲノム解析とは、いろんな環境から微生物群集由来のDNAを取ってきて配列を読んで、ずたずたの配列からバーチャルなゲノム配列を組み上げ、このバーチャルのゲノム配列を使って様々な解析をする技術になってきています。

森:このようなバーチャルなゲノム配列は MAG (metagenome assembled genome) と呼ばれ、いま大変重要視されています。このMAGと単離菌のゲノム(昔ながらのゲノム解読の結果)とを合わせて統合したデータベース「Microbiome Datahub」をJST-NBDCの「統合化推進プログラム」の予算的サポートのもとで構築しております。
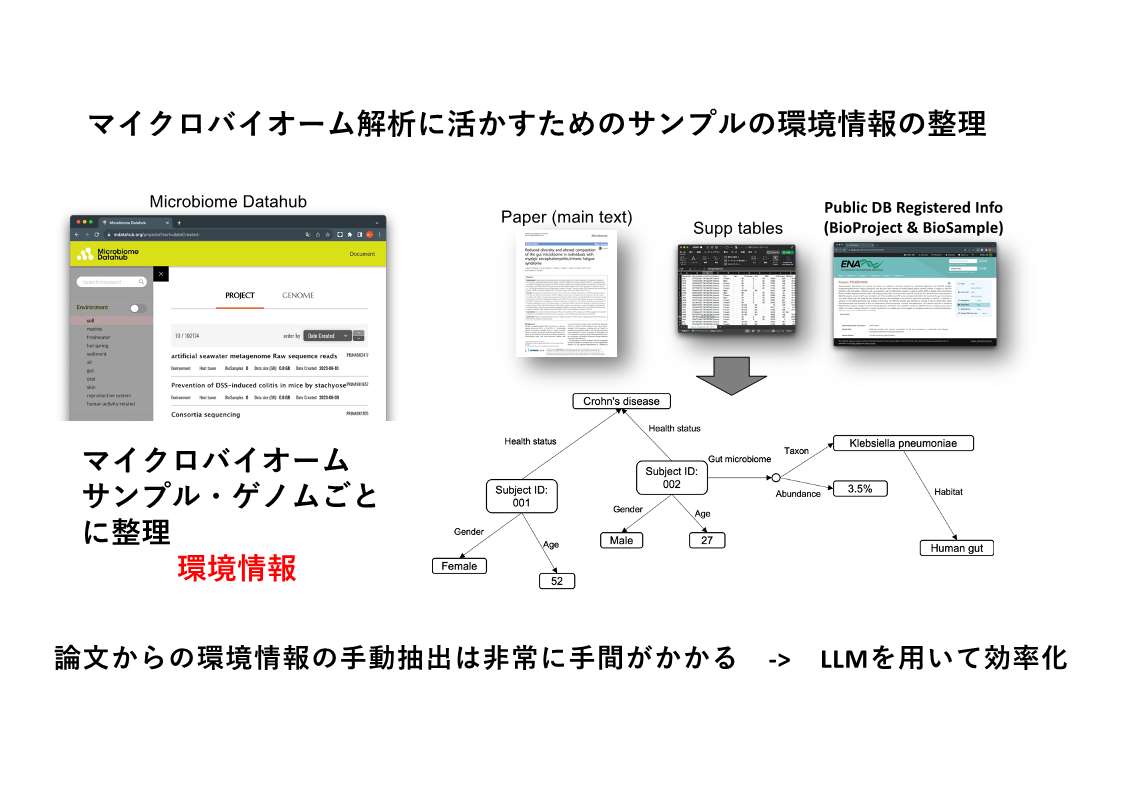
森:このデータベースのコアは、ゲノム配列と環境情報です。どういう微生物をどういう環境(土壌、人の腸内、それとも皆さんのPCの上)から採取したのかなど、非常に雑多な環境情報を紐づける必要があります。情報ソースは、「論文とその論文サプリメンタル情報」ならびにサンプルのメタデータがデータベース化されている「BioSampe」および「BioProject」の3つです。
ただ、論文やデータベース中のデータは、基本的に構造化されていません。このため、自然言語情報を何とか処理して綺麗なデータとして抽出する必要があります。これが今まではなかなか難しく、我々も専門のキュレーターの方を雇って、何年間も、論文から情報抽出に取り組んできました。しかし、近年のLLMを用いて効率化できるのではないかということで、我々もツール等を開発し、データ抽出をおこなっています。
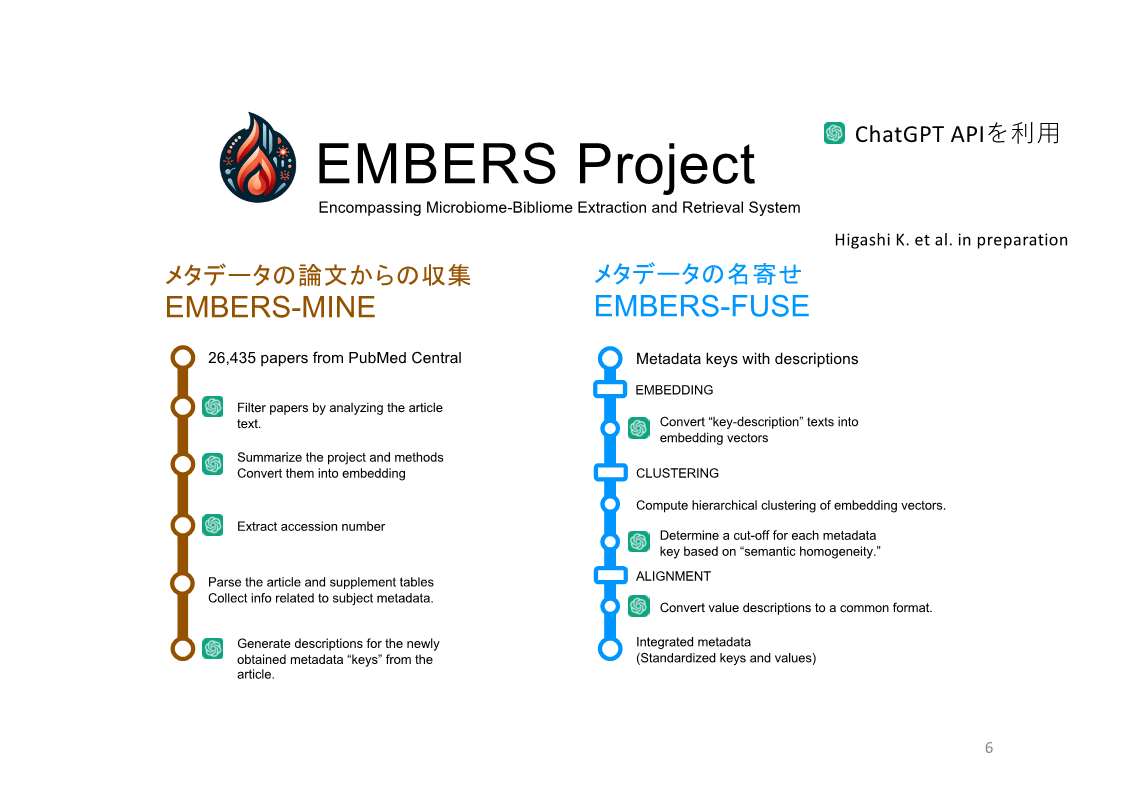
森:それがこのEMBERS Projectでして、来週にもBiorXivにプレプリント論文を投稿できる状態で、そのタイミングでGitHubにてコードも公開する予定です。
本ツールではPythonスクリプトおよびChatGPTのAPIをヘビーに使っています。PubMed Central に収録されている様々なメタゲノム関連の論文をXML形式でダウンロードし、論文の文字列情報をChatGPT APIに入力し、当該論文がどういうトピックを扱っているかを要約したり、各サンプルの環境情報などをJSON形式で出力したり、といったことをしています。また、その環境と判断した説明を付与させ、論文に紐づいたデータの名寄せをするツールも作っています。詳しい説明は、時間の都合上省きます。
EMBERS Projectのプレプリント論文およびGitHubリポジトリは、本ブログ記事掲載時点で以下の通り公開されています。

森:そうやって処理をした結果、2万数千の論文における研究がどういう実験条件なのか、どういう環境由来のデータなのかが網羅的に1つの2次元プロット図として見られるようになりました。各点が論文で、それぞれの実験条件、環境情報が閲覧できるようになっています。

森:ライフサイエンスに限らず、論文出版の文化があって大量に論文が蓄積されているということは共通かと思います。データベース開発者としては、今までどうやって論文から情報を抽出してデータベースに反映するかが課題でした。しかし、この1-2年、LLM技術、生成AI技術を使うことで相当程度簡素化できそうになっており、いろんな方々がツールを作っています。このあと数年で、データベースのコンテンツは非常に充実するだろうと考えられます。しかし、そのデータベースを一体誰が使うのか、何のために作って維持していくのかを考えないといけないと思います。
話題提供4:AIでなんでも解決できるのか?(東京科学大学・大上 雅史)

大上:東京科学大学の大上 雅史と申します。どうぞよろしくお願いいたします。私からは「AIで何でも解決できるのか」という内容でバイオインフォマティクスのお話をさせていただきたいと思います。

大上:私はコンピューターサイエンスをバックグラウンドとしており、研究ではずっとバイオインフォマティクスに携わってきました。2024年10月に、所属大学名が東京科学大学に変わりましたので、皆さんどうぞよろしくお願いいたします。
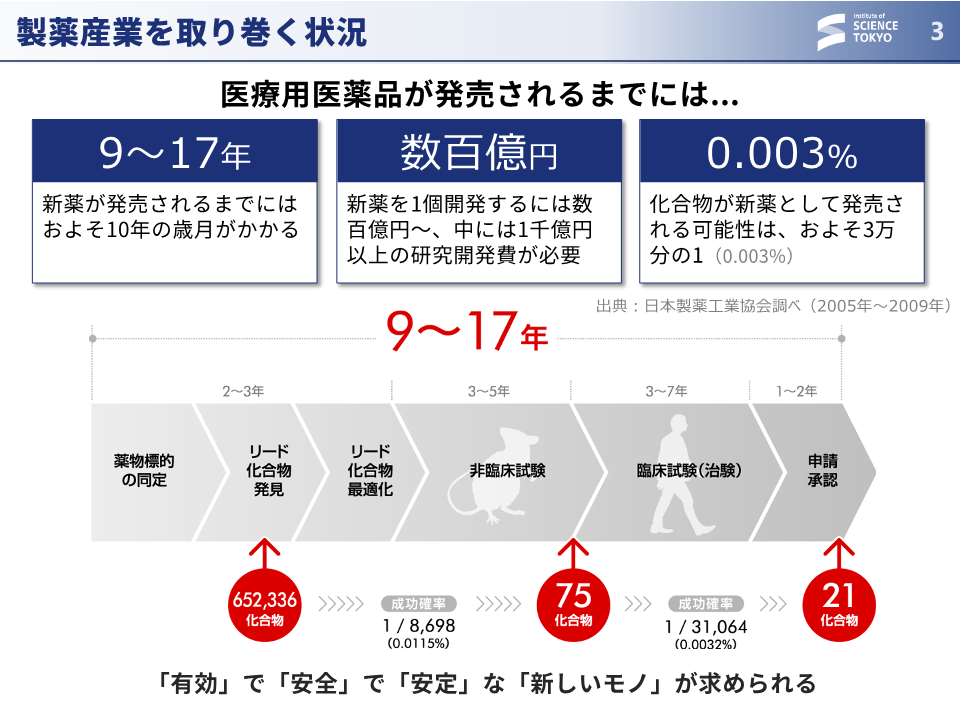
大上:バイオインフォマティクスに取り組みながら、最近は製薬企業等で行われる化合物探索の問題を多く手掛けていることもあり、「医薬品を作るのは大変ですよね」という話題を最初に取り上げることが多いです。医薬品は多額のコストとすごく長い年月をかけて作られますので、できるだけ最初の開発ステップにおいて、後のステップで失敗しないような完璧な化合物を(理想論なのですが)提案できると嬉しいよねということで、そのような化合物をどうやってAIもしくは計算技術で作りましょうという話をよくしております。
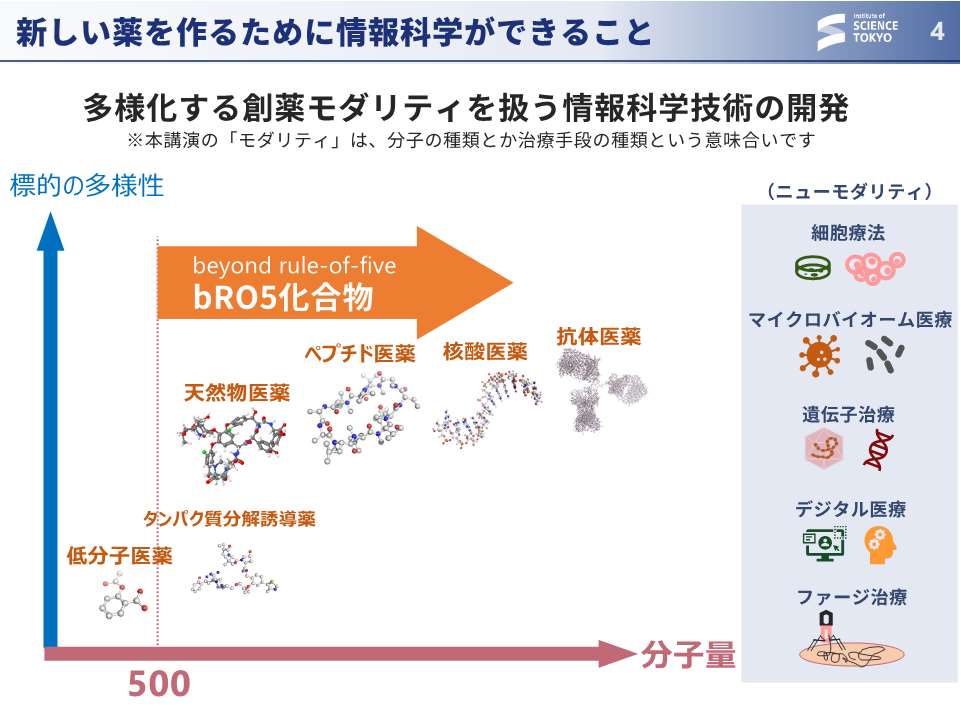
大上:近年では、薬になりそうな化合物の種類がすごく増えました。我々の文脈で「モダリティ」と呼ぶのですが、例えば、低分子、ペプチド、抗体、そういういろんな分子に対応していろんな組み合わせ、いろんな考えをどんどん適用していきましょうという話になります。基盤モデルのような技術が広く活用できると創薬にとっても嬉しいわけです。

大上:ただ、AIで何でもできるかと言われると、何でもはできないわけです。データがあればできそうなことあるのですが、データがあろうが難しそうなタスクというのも、もちろんたくさんあります。よくある例としては、データが十分にあるように見えて、実は知らない空間がたくさんあるというケースです。例えば、生物学を全て完璧に知っていたとしても、知らない惑星の生物の写真を見て名前を当ててくださいって言われると無理なわけです。そういったそのデータの量、多様性、また適用範囲 (そのデータでどういうことができるようなるのか) はきちんと考える必要があります。
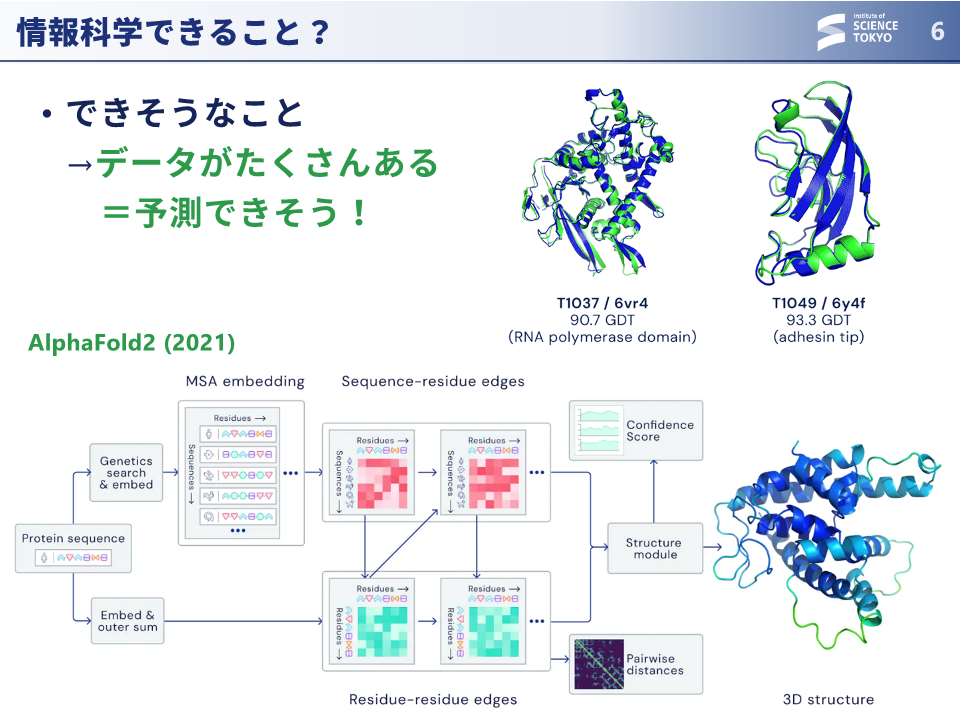
大上:近年の情報科学でできそうなことの1つに、皆さんご存知の AlphaFold があります。構造生物学によってたくさんの立体構造が解かれた結果、気合いでどうにか予測できるようになったわけです。
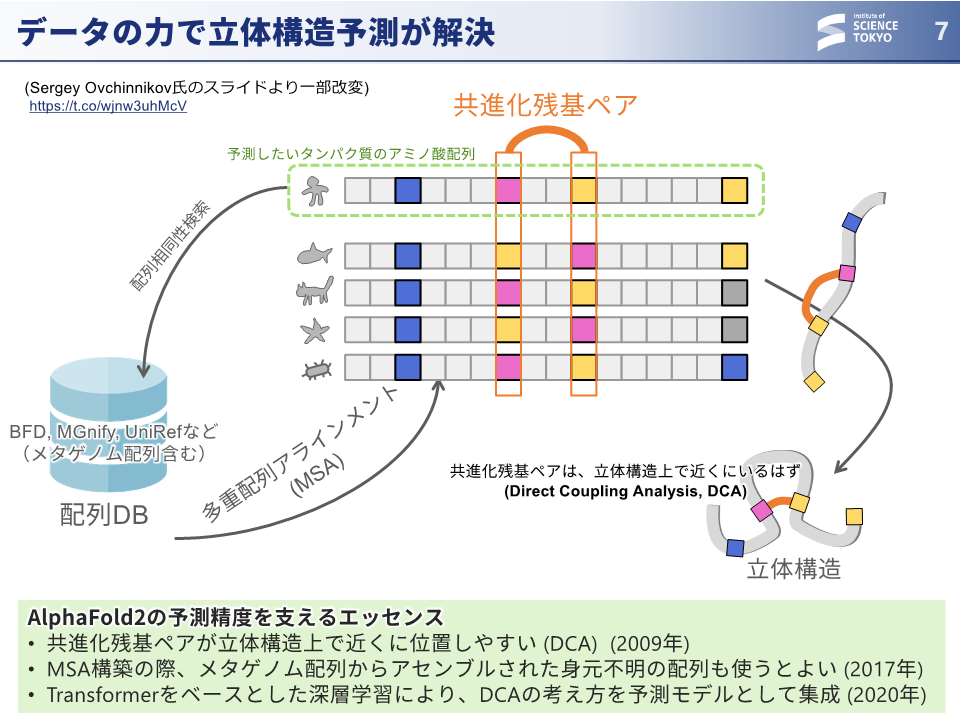
大上:AlphaFoldの中身はTransformerですが、このTransformerをどう使ったかが重要です。AlphaFoldにおいては、アミノ酸配列の共進化の関係が立体構造とよく相関することが分かっていたので、じゃあ頑張ってデータとしてたくさんかき集めて、深層学習を行なったらうまくいったという流れでした。AlphaFoldは幸運なシナリオでした。
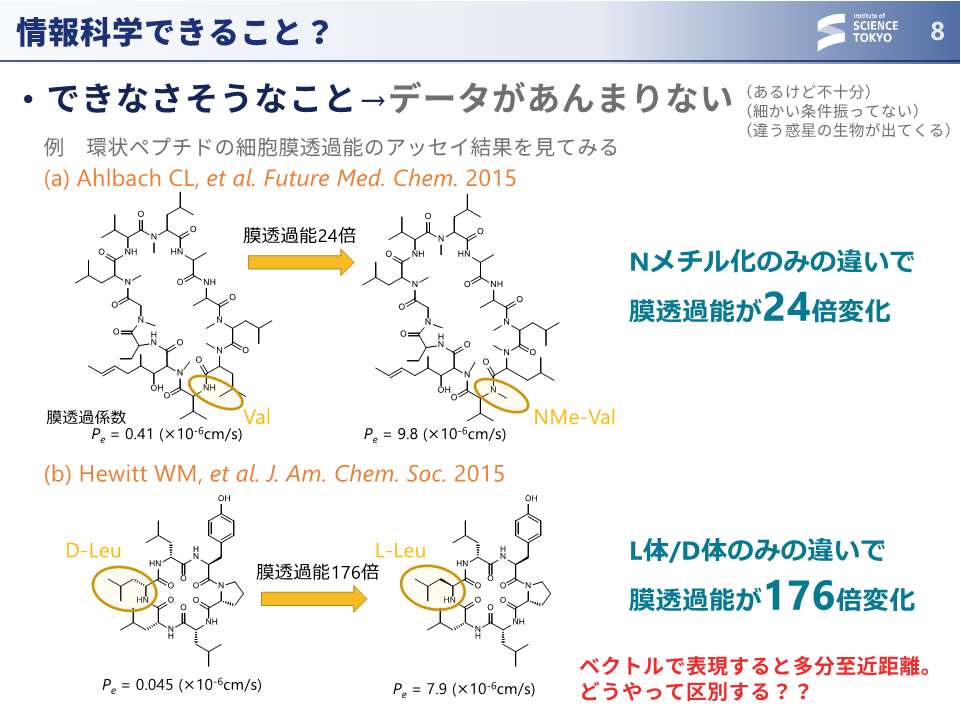
大上:しかし、当然、できないこともたくさんあります。よく挙げられるのが、化合物の活性が構造の微細な違いで変わるケースです。こちらのスライドで紹介しているのは、環状ペプチドが細胞膜を通るか通らないかという実験の結果です。ちょっと見ても構造の違いが分からないかもしれませんが、ここ (スライド中段の黄色丸内) だけ少し違っていて、Nメチルが入ってるだけで結果が24倍変わります。こちら (スライド下段の黄色丸内) は、光学異性体、D体とL体が違うだけで、176倍も結果が違うケースです。これらは、仮に化学の基盤モデルでベクトル化しても2つの化合物は隣同士になるはずで、すごく近いデータサンプル間でこれだけ違うという結果をどうやって識別しますかというのは、永遠の課題めいたところがあると思います。
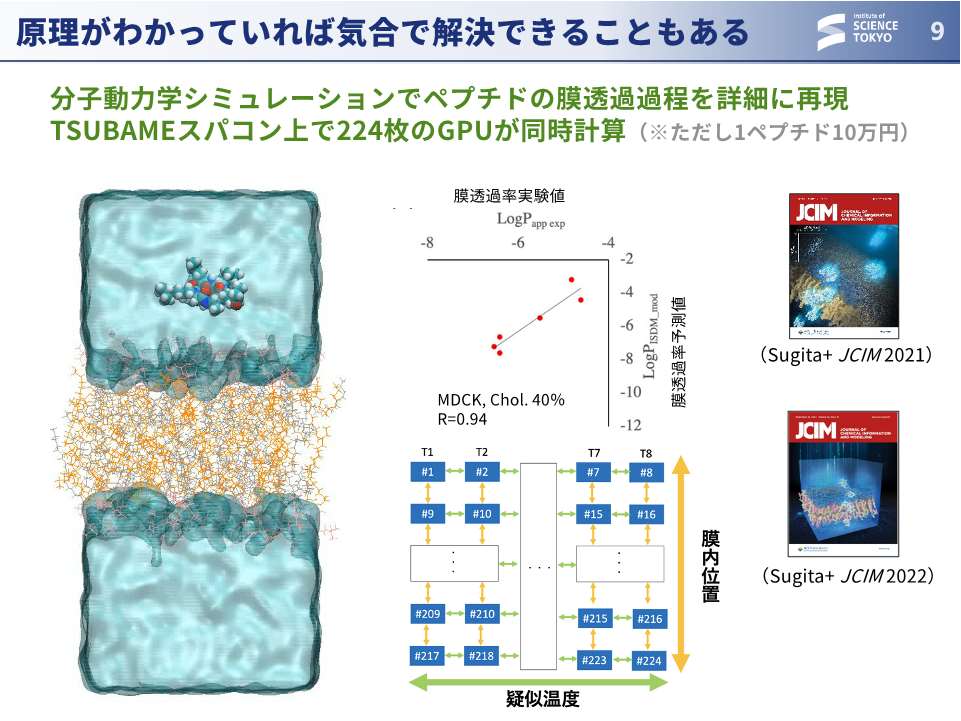
大上:ですが、これは実は物理化学的な現象ですから、原理が分かっていれば気合で解決できることもあります。我々の成果でもあるのですが、分子動力学シミュレーションによって気合でシミュレーションして計算するというのも一つの解です。ただ、GPUを同時に200枚使い、1個のペプチドだけで計算に10万円ぐらいかかるので、実験する方が安い。計算機がもっと進化してくれないと実用的ではありません。
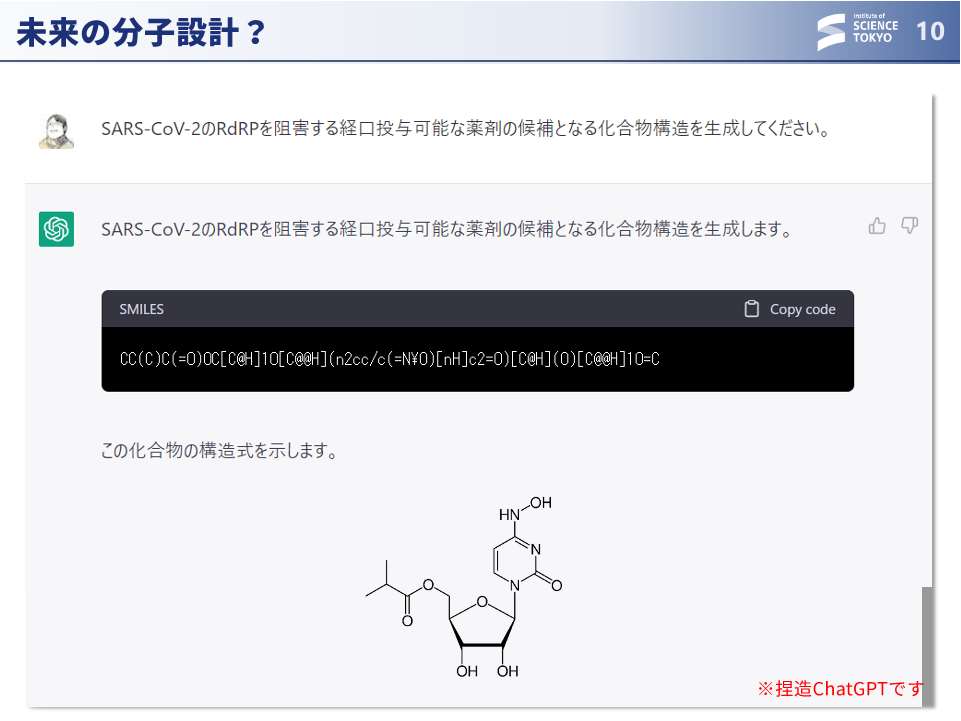
大上:AIの分野でも、例えば、ChatGPTのような技術で新しい分子をどんどんデザインできたらよいのですが、実現にはまだまだ時間がかかりそうです。

大上:バイオインフォマティクス、バイオインフォマティシャンとして、できること・できないことの見極めは重要視されるところです。
また、牛久先生がご専門のNLPやCV、AI分野からいろんな技術が出てきた時にどうやって応用分野へ持ってきますかというところも重要になると思います。また、二階堂先生がおっしゃっていた、すごく小さな変化というのは検出が難しいので、そういうところに適用できる技術が必要になっていくと思っています。
今後、AI技術がどのように使われるかという点では、もっと痒いところに手が届いて欲しい。個人差や点変異の影響をきちんと予測し、その予測根拠を述べてくれるものが欲しい。しかし、どんなデータがあるとそれができるかは誰もよく分かっていないので、どう考えていこうかという点が課題です。さらにはそうした細かいデータをたくさん集めたら、今度は大量の計算機資源がもっと必要になってきますので、計算機センターもどんどん大きくしていかなくてはいけません。 話題提供は以上です。ありがとうございます。
話題提供5:生成AIは生命科学の何を変えるのか(千葉大学・大田達郎)

皆さんこんにちは、千葉大学の大田でございます。本日は、トーゴーの日シンポジウムの開催、おめでとうございます。シンポジウムにパネリストとしてお呼びいただき、大変光栄でございます。私からは、AIは生命科学の何を変えるのかということでお話をさせていただきたいと思います。

簡単に自己紹介ですけれども、千葉大学の医学研究院の人工知能医学教室に所属しておりまして、生成AIもユーザーとして色々な目的で使わせていただいております。元々の専門はバイオデータベース、オミクスデータ解析のプラットフォームの開発をやっておりまして、千葉大学に着任する前はライフサイエンス統合データベースセンターで長くお世話になっておりました。


今日こういうタイトルでですね、「AI+ロボティス+データベースが変える生命科学」ということで、変えることは決まってる、では何を変えるんですかということは書いてない、きちんと言った方がいいのではないかと思っております。

今日は午前中から様々な講演がありました。生成AIはすごい、皆さん知ってます、すごいのですが、解決する問題いっぱいありますよねということを提起しておきたいと思います。
一番有名なのはChatGPT。OpenAIですがオープンではないというのは、非常に気に入らないところです。非常に強力ですが、バックエンドが変わったタイミングなども分からないわけですね。そういったものに依存して研究をするというのは、透明性、またセキュリティ――OpenAIのサーバーにデータを渡さなければいけない――の問題もあります。
また、非常に強力なGPU計算機、V100、A100、H100とどんどんパワフルなGPU出てきていますけれども、特定の企業によるそういう計算機の供給が寡占状態なのはいかがか。また、電力問題が叫ばれてますけれども、こんな膨大な電力をAIだからといって消費していいのという問題もあると思っています。
それから、アプリケーションの話ですけれども、医学部で色々な先生とこういった話をしますと、やっぱりその事実誤認や正確性に関するリスク――「患者さんが使って嘘言われちゃって」というのは非常に困るわけです。また、AIは、午前の講演でもありましたけれども、インストラクション・チューニング (Instruction Tuning) をするのですが、人間の価値観とAIの価値観はどこまで本当にちゃんと沿っているのかという問題も色々な論文で既に議論が始まってるところです。

もしそれらの課題が解決したとして、研究への応用の障壁となるのは出力の正確性かと思います。
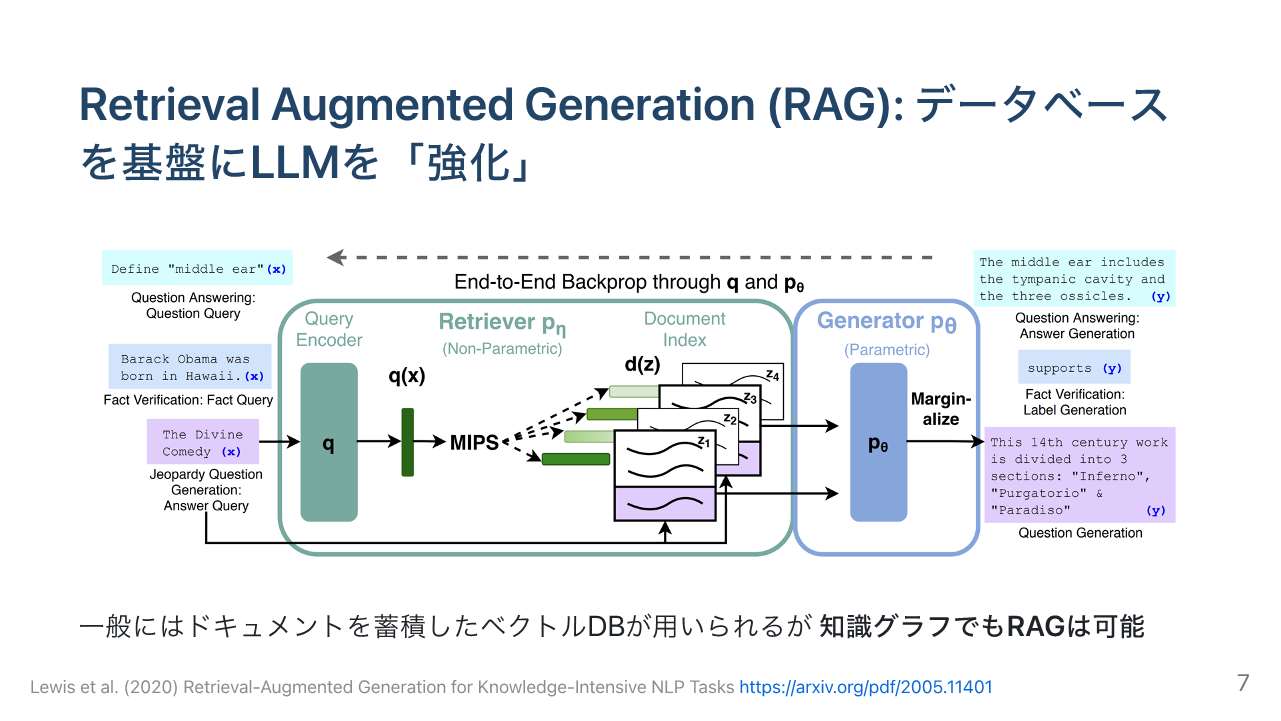
1つ、重要な技術としてRAG (Retrieval-Augmented Generation) 技術が盛んに使われております。LLMに直接聞いて答えるのではなくて、聞く時にその聞いた質問や色々なそのユーザーの入力に関連する情報をデータベースから取ってきてLLMに与え、データベースから取ってきた情報を元に出力を生成するというものです。単にモデルの中にエンベッドされた重みの情報で出力するよりも、より事実に即したデータを出してくれると考えられています。一般的には、社内文書をベクトルデータベースに入れて細切れにした文章から関連するチャンクを取ってきて出力するのですが、知識グラフでもRAGは可能であると思っています。

1つ面白い話がありまして、有名な「Thinking, Fast and Slow」(邦題:ファスト&スロー)というダニエル・カーネマンの本のなかで、人の思考は直感的な「システム1」と時間のかかる論理的なシステム2という2つのモードの組み合わせでできていると紹介されています。LLMはパターンから即座に出力するものなのでシステム1、データベースの構築で目指してきた蓄積されたデータから推論を行うようなものがシステム2に当たるのではないかと思っています。
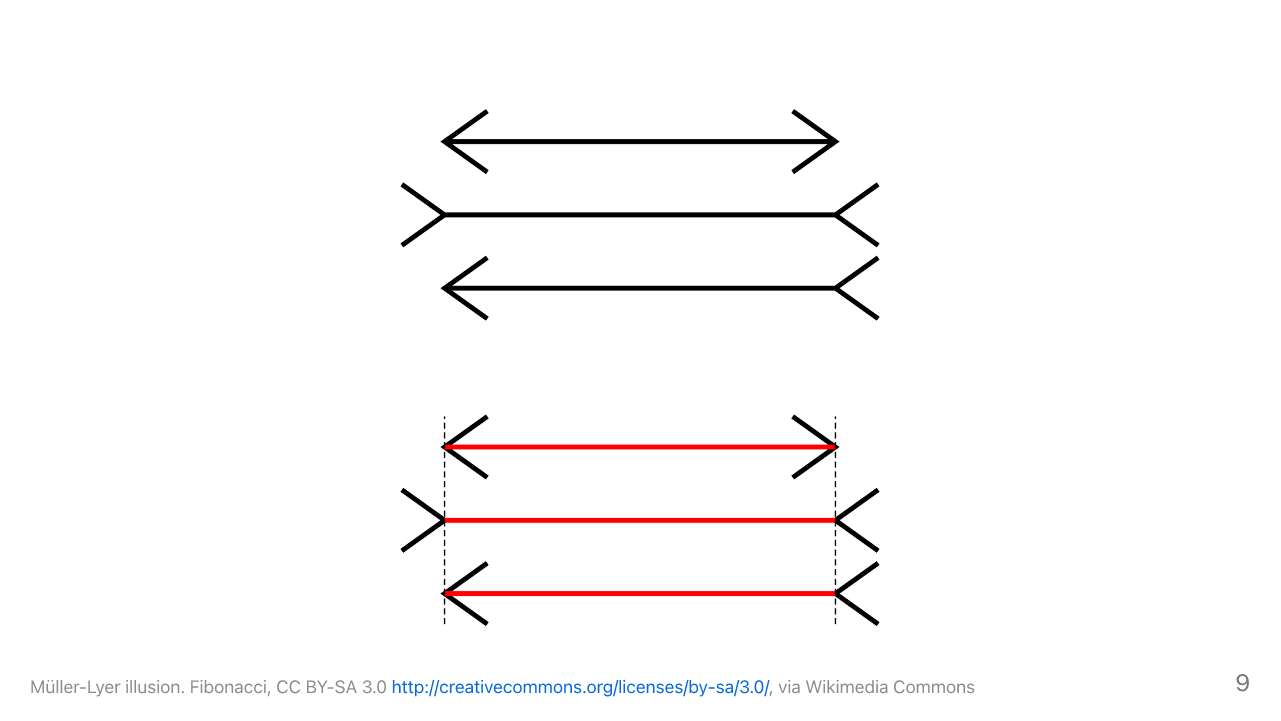
有名なミュラー・リヤー錯視では、矢印の真ん中の線が、知っていてもこちらの方が長く見えてしまう。長く見えてしまうのはシステム1で、同じに見えるというのはシステム2なんですね。間違えてしまうところを別の情報で補完しているわけなので、データベースが担うのは情報の正確性を担保する部分ではないかと思っています。

近々、生成AIは幻覚を見なくなるだろう、では生命科学のボトルネックの解消に必要なものは何でしょうか。

科学者、仮説構築、計測技術、サンプリング、実験、論文出版、社会からの需要への対応、色々挙げられます。AI、ロボット、データベースはこのうちのどれを助けるのかというのを考えなければいけません。

そういった色々な問題や考えるべき点がある中で、将来の生命科学を左右するキーワードとして私が提案したいのは、観測・予測をするということです。
先ほども話がありましたが、すでにあるものはAIがなんとかしてくれるでしょう、ではこれから起きるものはどうするんですかということで、インフラ、データの話もありました。
それからプログラムAIの自律性という点。高木先生が過激にと言われましたので提起しますが、人間がAIを監督するのか人間がAIに監督されるべきなのかをよくよく考えた方が良かろうと思います。先ほどSakanaAIの話が出ましたが、つよつよAI研究者が出てきた時に、人間はサイエンスをやらなきゃいけないんですか、やらなくてもいいんじゃないでしょうかということを考えていく必要があると思っています。以上です。
前編:話題提供1(牛久氏/二階堂氏)、中編を通じ、5名からの話題提供をご紹介しました。後編は、いよいよ議論です。
