Biomedical Linked Annotation Hackathon 7(BLAH7)参加報告
NBDC研究員の建石です。2021年1月18日から22日に開催された第7回Biomedical Linked Annotation Hackathon 7(BLAH7)に参加しました。
コロナ禍でのハッカソン
昨年このブログにBLAH6の参加報告をいたしましたが、今年も昨年同様、医学・生物学関係のテキストマイニングやそのために必要なアノテーションの作成や解析に関連する技術の共同開発や情報交換を行うハッカソンとして7回目のBLAHが行われました。当初は、昨年同様JST東京本部2階の共創スペースで行う予定だったのですが、新型コロナウイルス感染症(COVID-19)のために国外からの参加が難しいということから、昨年秋に「オンライン中心、ただし、国内参加者はライフサイエンス統合データベースセンター(DBCLS)柏サイトでオフライン参加可能」というハイブリッド形式に変更しました。開催直前にはさらに、国内での流行拡大、再度の緊急事態宣言を受け、完全オンライン形式としました。
COVID-19の世界的流行を受け、今回のBLAHでは特別テーマとして「自然言語処理(NLP)技術を結集するとCOVID-19との戦いにどこまで役立つことができるか」という問いを立て、COVID-19に関連するアノテーション・マイニングに関するプロジェクトを中心とした活動を行いました。米国国立生物工学情報センター(NCBI)がリリースしているCOVID-19関連文献セットLitCovidに対して、PubTator(NCBI)、OGER(スイス Istituto Dalle Molle di Studi sull'Intelligenza Artificiale:IDSIA)、PubDictionaries(DBCLS)の3つのツールで基本的な生物医学エンティティの付加(アノテーション)を自動的に行った文献コレクションを提供し、新たなアノテーションの追加やアノテーション済み文献を使った情報抽出、また、LitCovidの利用以外でもCOVID-19との戦いにつながるシステムの開発を目指しました。
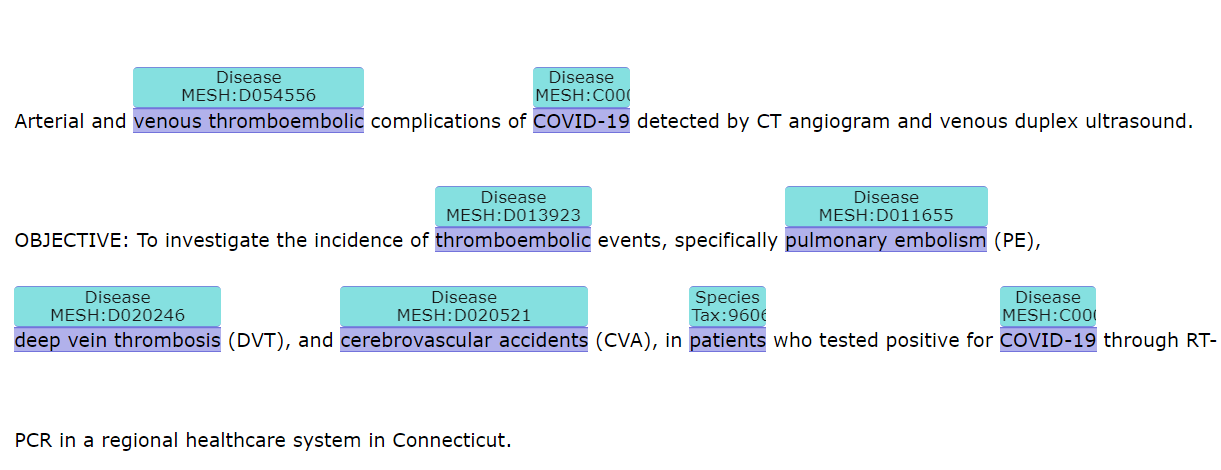
LitCovidに含まれる論文のアブストラクトに、PubTatorシステムを用いて自動アノテーションをした結果の一部
オンライン開催の特徴
オンライン開催に伴って、今回のBLAHでは例年の公開シンポジウムは行わず、ハッカソン参加者からのプロジェクト紹介を事前収録のビデオとZoomで行うのみ、としました。
また、参加者同士の連絡・交流手段としてSlackのチャンネルを用意し、Remoという複数のテーブルごとに分かれて会話のできるリモートイベントツールも試用してみました。ただ、Remoは、中国からアクセスできない、IE/Edgeからアクセスできない、通信が重い、という問題があり、参加者一同が会する全体会議には使えませんでした。
当初の予定ではプロジェクト紹介・ラップアップなど全体会議は、時差を考慮して日本時間の8時からと22時からの2回行うことにしていましたが、発表者に希望を募った結果、22時からのみとなりました。今回アメリカからの参加者が1人だけだったのでヨーロッパとアジアから参加しやすい時間帯が選ばれた、ということでしょう。アメリカ、と言えば、日本時間の1月21日の午前中、通信がとても重くなりました。大統領就任式の影響だったかもしれません。
月曜日に行われた最初の全体会議であるプロジェクト紹介ではZoomを利用して各プロジェクトの紹介と質疑応答を行い、最後に記念撮影としてZoomの参加者画面のスクリーンショットを撮りました。残る2回の全体会議、水曜日の中間ラップアップと最終日のラップアップも、同様にZoomで行いました。
プロジェクト紹介と最終日のラップアップの様子は統合TVから公開予定です。プロジェクトの紹介についてはBLAH7のページもご覧ください。
ハッカソンの進め方とプロジェクトの例
ハッカソンでは各プロジェクトに分かれて開発を進めました。独自にZoomなどのチャンネルを用意して利用したプロジェクトが多かったようですが、Remoのテーブルも使われていました。Remoにはヘルプデスクも設けたほか、雑談・待ち合わせといった目的にも利用されていました。
特別テーマのCOVID-19関係では、LitCovidに対して遺伝子発現(LitCovid_AGAC)、糖鎖(LitCovid_Glycan-Motif-Structure)などのアノテーションを行うプロジェクトや、LitCovid_OGERのアノテーションを利用してCOVID-19に対するレムデシビルなどの薬効に関する情報抽出を行うプロジェクトがありました。
BLAH7の成果として、LitCovidセットに種々のアノテーションを行ったコーパスがPubAnnotationから公開されています
また、複数の言語でアブストラクトが用意されている論文からパラレルコーパス(同じ内容を複数の言語で記述した文書の組のセット、機械翻訳システムの学習などに利用される)を作るプロジェクトが2つあり、うち1つはCOVID-19関連の英語とポルトガル語のパラレルコーパス、もう1つはCOVID-19に無関係なものも含めて英語以外の言語のアブストラクトを集めたコーパスをつくるものでした。英語以外、の中には日本語も含まれていて、「日本語のアブストラクトのあるPubMedエントリー」があるのだということを今回初めて知りました。
さらに、COVID-19とは直接の関係はありませんが、希少疾患の症例報告のコーパス作成や、PubMed文献の構文解析のためのコーパスの作成も試みられました。
私自身は「LitCovid-PubTatorセット(英語)でアノテートされたMeSH Termに対し、日本語訳をつける」というプロジェクトに参加しました。
英語のアブストラクトをDeepLで機械翻訳した日本語アブストラクトと原文をパラレルコーパスとして、相互情報量による方法、辞書(WikidataからMeSH IDを付与された項目のラベル、BLAH6で作成した辞書の見出し語、KEGG Medicusのラベル、Human Phenotype Ontologyのラベル)による方法を併用して、MeSH IDの付与された用語(MeSH Term)に日本語訳を与えることを試みました。LitCovidセットに50回以上出現するMeSH IDについては複数のソースから来た日本語ラベルのうちから3人で協議してMeSH Termの訳語を選びました。5805種類のIDに何らかの日本語訳がつき、うち、人の目でチェックができたものは1039種類でした。この数は少ないように見えますが、LitCovid上のアノテーションの出現回数に対して、チェック済みの語を使うと94.63%、全体では98.99%に対して訳語をつけることができました。
本家NCBIのMeSHは更新が速く、「COVID-19」という語は2020年2月には既に登録されていましたし、その後もCOVID-19関連用語が追加されていたりしますが、日本語の辞書でMeSH番号を参照できるものは追いついていません。今のように新しい発見が日々行われている状況では、今回の試みのように手軽に辞書を構築することが必要になってくるのではないかと思います。
終わりに
やっぱりリモートだとなんだかかゆいところに手が届かない、直接会いたいよね、という気持ちもありました。時差の関係で慣れない時間帯に仕事をする不便さもありました。でも、このようなイベントを中止せずに済んだのはよかったですし、バーチャル技術の発達に感謝しています。
BLAHの各プロジェクトの成果は昨年同様Genomics & Informatics誌の特集号として6月に公表される予定です。
関連リンク
- BLAH7 | 統合TV
プロジェクト紹介の動画
 Licensed under a Creative Commons 表示4.0国際 license
Licensed under a Creative Commons 表示4.0国際 license
©2021 建石 由佳(国立研究開発法人科学技術振興機構バイオサイエンスデータベースセンター)
