【プログラミングなし】ワードクラウドで「トーゴーの日シンポジウム」のキーワードを可視化する方法
みなさま、はじめまして。NBDC広報チームの森です。
現在NBDC広報チームは、10月5日(金)に日本科学未来館で開催する「トーゴーの日シンポジウム2018」に向けて、準備の最終段階に入っています。
この「トーゴーの日シンポジウム」は、生命科学分野のデータ統合にまつわる問題をともに考え、議論を深めるためにNBDCが毎年開催しているもので、今年は医学関連のデータベースを中心にプログラムを組み立てています。
広報チームの一員として、どうすればこのシンポジウムに対してみなさまに興味・関心を持ってもらえるか、毎年頭を悩ませているのですが、ひとつの試みとして昨年より、ワードクラウドによるシンポジウムのキーワードの可視化を始めました。
ワードクラウドというのは、ご存知の方も多いかと思いますが、文章等のテキストデータを単語ごとに分割し、抽出したそれぞれの単語をテキスト中での出現頻度に応じた大きさで図示する手法です。テキストをすべて読まなくても、頻出するキーワードを可視化することで、そのテキストが扱うテーマを直感的に把握することが可能になります。
(Google画像検索で、具体例をいろいろとご覧いただけます)
プログラミング言語の知識をお持ちの方であれば、RやPythonといった言語でワードクラウドを作成するためのライブラリ(ある機能を実現するのに必要な複数のプログラムをひとまとまりにしたもの)を利用することができますが、あいにく筆者にはそういった知識が著しく欠乏しております。
そこで、あれこれ調べた結果、ウェブツールと一般的なオフィスソフトのみを使ってワードクラウドを作成する方法にたどり着きました。
本記事では、「トーゴーの日シンポジウム」を題材として、
- プログラミング言語は難しそう
- でも手持ちのテキストのキーワードを可視化してみたい
という方に向けて、手軽なワードクラウドの作成方法を紹介します。
ただし、今回紹介する方法では、配色に意味づけをしたり、単語の表示角度を設定したり、といった調整はできません。そういった工夫をしたい方は、ぜひ前述のプログラミング言語の活用に取り組んでみてください。
ワードクラウド作成の目標設定
さて、トーゴーの日シンポジウムでは、招待講演や口頭発表に加えて、データベースの開発・運用・利活用に関するポスター発表(2018年は63件)を実施するのが、一つの大きな特徴です。
このポスター発表については、発表申込の際に500字程度の要旨を提出していただき、ウェブ上で公開していますので、その要旨の全件において頻出する名詞(固有名詞を含む。代名詞を含まない)を対象にワードクラウドを作成することで、シンポジウムにおける重要なキーワードを可視化したいと思います。
さらに、ただ可視化するだけではあまり面白くありませんので、
- NBDCが開催した第1回(2011年)と今回(2018年)のワードクラウドを比較することで、シンポジウムにおけるキーワードの変遷を捉える
ことを、目標として設定してみましょう。
事前の予想としては、以下のように考えています。
- NBDCの共同研究先やファンディング先の研究チームには、毎年ポスター発表をしてもらっており、その数が全体の中で大きな割合を占めるので、出現頻度最上位のキーワードには大きな違いはないのではないか
- ただし研究自体の進展や、技術発展など研究を取り巻く環境の変化により、中位のキーワードにはある程度の変化がみられるのではないか
ワードクラウド作成の方法
ワードクラウドの作成は、大きく分けて以下の2ステップで行います。
(1)テキストを単語ごとに分割し、出現頻度をカウントする
(2)ExcelとE2D3を使って頻出キーワードを可視化する
詳しい手順は以下で説明します。
(1)テキストを単語ごとに分割し、出現頻度をカウントする
[1.1] 2018年のポスター要旨の全文をWord文書に貼り付け、Shift-JISもしくはUTF-8エンコードのテキストファイルとして保存する
※「作成方法の流れだけ知りたい」という方は、まずはポスター1件分の要旨で同様の作業を行ってみてください。
[1.2] 無料でテキストデータの解析(単語への分割や出現頻度のカウントを含む)を行ってくれるウェブツール「ユーザーローカル」のサイトにアクセスし、1.1で作成したファイルを選択する
[1.3] 「テキストマイニングする」をクリックすると、解析結果の画面が表示される
※実は「ユーザーローカル」はそのままワードクラウドも作ってくれますが、品詞ごとに単色、かつ単語の表示が一方向なので、少し味気ないです。
[1.4] 単語の出現頻度をShift-JISエンコードのCSVファイルとしてダウンロードし、ファイルをExcelで開いて確認する
[1.5] 名詞、動詞、形容詞が出現頻度順にリストアップされているので、そこからA列が「名詞」となっている行について、B列とC列を別シートにコピー&ペーストする(下図の赤枠部分)。さらに、ペーストしたリストの中から「これ」「これら」「われわれ」のような代名詞を目視で探して、その行を削除する
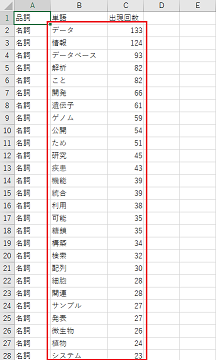
ここまでの作業で、ポスター要旨全文において頻出する名詞(固有名詞を含む。代名詞を含まない)を出現頻度とともにリスト化することができました。
(2)ExcelとE2D3を使って頻出キーワードを可視化する
[2.1] ExcelのストアからE2D3をダウンロードする
※E2D3は、D3.js(データの可視化を行うためのJavaScriptライブラリ)をExcel上で利用するためのアプリケーションで、日本発のオープンソースソフトウェアです。ダウンロード方法および詳しい使い方については、E2D3プロジェクトのウェブサイトを参照してください。
[2.2] E2D3を立ち上げ、ワードクラウドテンプレートの「可視化する」ボタンをクリックする
[2.3] (1)で得た名詞リストから、今回は出現頻度上位50単語を選び、出現回数とともにコピーする。テンプレートのA2セルを選択し、「コピーしたセルの挿入(下方向にシフト)」を行う。元から入っていたデータはそのあと削除する
[2.4] 自動的にワードクラウドが表示される(下図)
※文字の大きさは出現頻度を反映しています。場所・向き・配色はランダムで意味を持ちません。
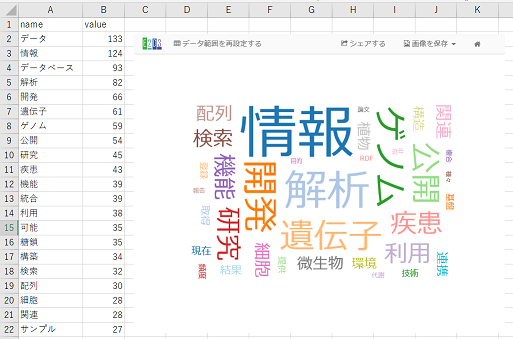
[2.5] すべての単語が表示されるように、適宜画像を拡大縮小する
※画像は毎回ランダムに変化します。出現頻度が高く、文字列が長い単語が表示されない場合があるので注意しましょう。例えば、上図では「データベース」が表示されていません。
[2.6] PNG形式等で「画像を保存」する
ここまでの作業で、2018年のポスター要旨全文における頻出キーワードを可視化することができました。
また、同様の作業を2011年のポスター要旨43件の全文について行うことで、こちらについてもキーワードを可視化することができます(下図)。


2011年ポスター要旨と2018年ポスター要旨のワードクラウドの比較
さて、前章で得られた2011年と2018年のワードクラウドを比較すると、出現頻度が特に高い単語(たとえば、「データ」「データベース」「情報」等)については、多少の順位の変動はあっても、概ね共通しているように見えます。
一方で、出現頻度がやや低い単語について、2011年に見られなかったいくつかのキーワード(たとえば、「疾患」「リポジトリ」「SPARQL」等)が2018年のワードクラウドに現れています。
それらのキーワードが出現した理由について、ここで詳しく考察することはしませんが、筆者の事前の予想はかなりいい線行っていたのではないかと自画自賛しております。
みなさまは、いかがお考えでしょうか?
まとめ
本記事では、ウェブツールと一般的なオフィスソフトのみを使って、ワードクラウドを手軽に作成する方法を紹介しました。また、作成したワードクラウドからどのような考察が可能であるかについても、(非常に浅いものではありますが)実例をお示ししました。
テキストデータのキーワードを可視化したい、とお考えの方の参考になれば幸いです。
また、本記事で「トーゴーの日シンポジウム」に興味を持たれた方は、今年の事前参加登録はすでに締め切りましたが、当日参加も可能ですので、ぜひ会場まで足をお運びください。今回作成したワードクラウドも、事務局ポスターとして掲示いたします。
 Licensed under a Creative Commons 表示4.0国際 license
Licensed under a Creative Commons 表示4.0国際 license
©2018 森亮樹(国立研究開発法人科学技術振興機構バイオサイエンスデータベースセンター)
