FORCE2019参加報告 ~オープンな科学やデータのために~
NBDCの大波です。
2019年10月15~17日にイギリスのスコットランド地方の都市、エディンバラでFORCE2019が開催されました。FORCE2019はFORCE11という組織が開催するオープンサイエンスについて議論を行うための年次会合であり、筆者は昨年に引き続きの参加となりました。
FORCE11の沿革や昨年の会合の様子については、前回のブログ記事「FORCE2018参加報告 ~オープンサイエンスの未来を考える会合に参加して~」をご参照ください。

FORCE2019の案内表示
初日のワークショップ
初日はプレカンファレンスとして、一般会員向けに数件のワークショップが開催されました。ハッカソンなどの共同開発ワークショップもあり、議論中心の二日目以降とは違った趣でした。筆者は午前と午後に開催された以下2件のワークショップに参加しました。
Citations needed: Wikidata and the scholarly publishing ecosystem
(要出典:Wikidataと学術出版のエコシステム)
「Wikidata」の解説と、そのデータ編集を実際に体験して学術情報の公開について議論を行うワークショップでした。Wikidataは、ネット上の市民参加型百科事典であるWikipediaを公開している、Wikimedia財団が出資している「データ」のインフラです。ここではWikipediaと同様に、誰もがあらゆる事物のデータを作成し編集することができます。ワークショップの中では、まずWikidataの概要の説明がありました。
例えばエディンバラで行われている祭、「フリンジ」は、各国のWikipediaごとに詳細な記事(英語版 https://en.wikipedia.org/wiki/Edinburgh_Festival_Fringe|日本語版 https://ja.wikipedia.org/wiki/エディンバラ・フェスティバル・フリンジ)(下図左参照)がありますが、Wikidataの場合は一つのIDだけが割り振られていて、どんな言語であっても「1つのURL https://www.wikidata.org/wiki/Q368176」(下図右参照)で示すことができます。
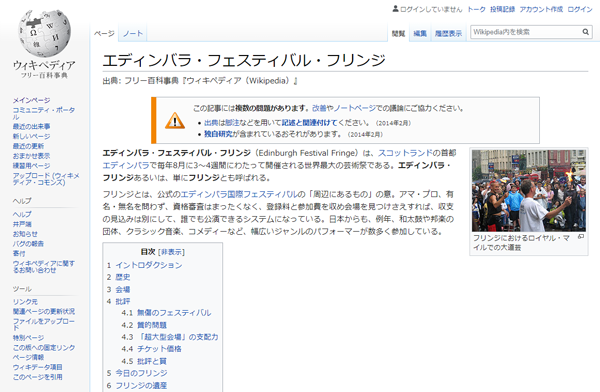
Wikipedia日本語版の「フリンジ」の記事。英語版や言語ごとに別の記事ページがあり、説明する内容も若干異なっている。
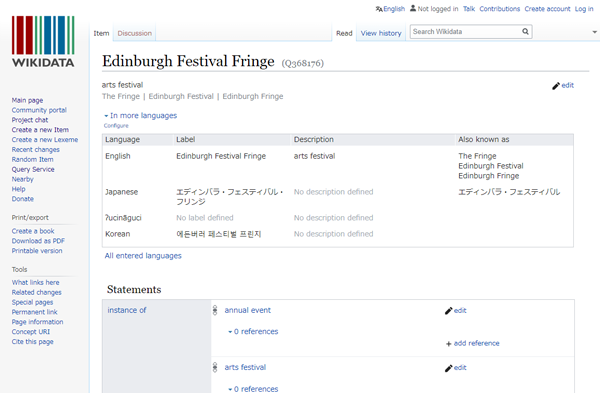
Wikidataの「フリンジ」の記事。全ての言語の内容が一つのページに記述されている。表現も自然文ではなく構造化された情報(例:「フリンジ」→「開始年」→「1947年」)で記述されている。
このような一つの概念と一つのIDが1対1で結びつけられる特徴は、セマンティクス(意味論)的にも重要です。さらにWikidataは、「概念」と「値」を「プロパティ」で結びつける三つ組の情報で構成されており、これはNBDCでも推進しているRDF形式のデータとして公開されていて、機械可読性にも貢献できます。
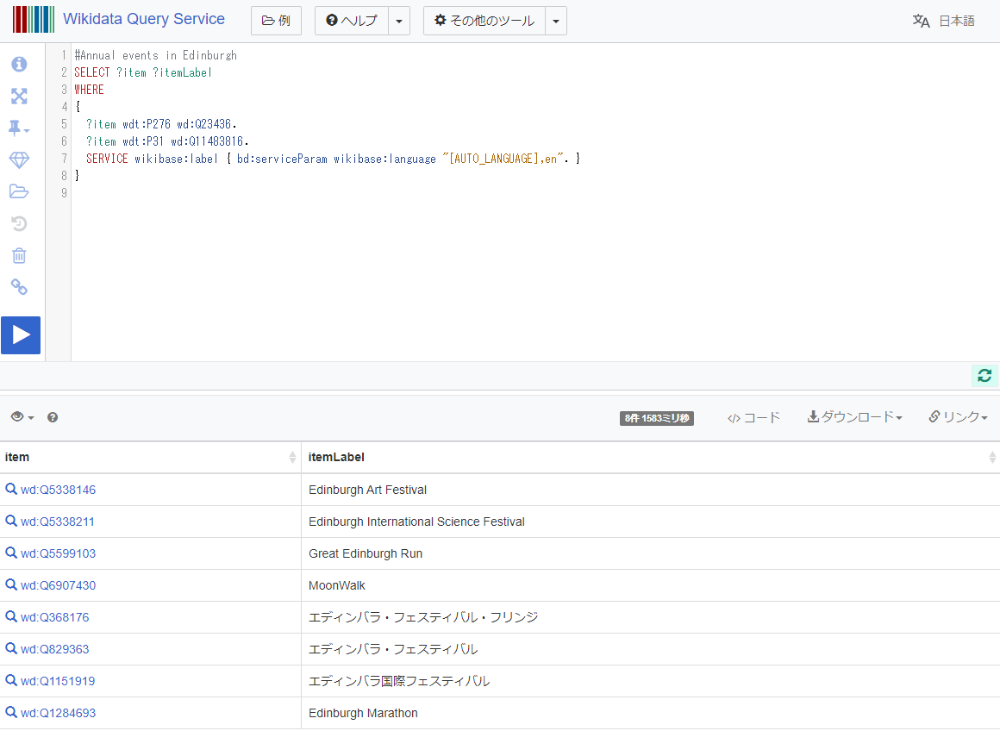
このデータを検索するためのSPARQLクエリの送信サイトも利用することができます。例えば「場所(ID:P276)」が「エディンバラ(ID:Q23436)」で、「定期的に開催されるイベント(ID:Q11483816)」に「分類される(ID:P31)」概念を検索するには、
#Annual events in Edinburgh
SELECT ?item ?itemLabel
WHERE
{
?item wdt:P276 wd:Q23436.
?item wdt:P31 wd:Q11483816.
SERVICE wikibase:label { bd:serviceParam wikibase:language "[AUTO_LANGUAGE],en". }
}
のように記述します。なお最後の wikidata:label の行では、一般のSPARQLクエリには無い独自の拡張がなされています(参考:https://fumi.me/2015/12/09/wikidata-query-service/)。そして左にある「▷」の実行ボタンをクリックすると、下図のようにフリンジを含む「エディンバラで定期的に開催されるイベント」のリストが得られました。求める情報を極めて論理的に導くことができます。
こういった情報を踏まえて、新たにデータを登録する体験会が開催されました。Wikidataにまだ登録されていない論文のタイトルリストから参加者それぞれが一つずつ選び、Wikidataにページを作って登録する作業を実施しました。筆者が作成したWikidataのページはこちらです。
最初はどのような「プロパティ」が存在するのか分かりませんでしたが、オーガナイザーからいくつかのツール(Wikidata:List_of_Properties、Wikidata Propbrowse、Property Explorer)が示され、入力時に豊富なサジェストが表示されるのもあって、意外と簡単に登録することができました。このワークショップでは、Wikidataの意義やセマンティックなデータの公開について理解を深めることができました。
この一方で、参加者から以下のような様々な意見や議論の提案があり、まだ発展途上な部分も見えたものの、終始ホットな場となりました。
- Wikidataの編集に使うツールの場所が分からない。
- Wikidataのデータの重複の可能性を調べるには?
→(回答)Googleで調べたり、記法(special: )等でチェックできる。 - 同じ分野の項目でも、使用するメタデータが統一されていない場合がある。
- テキストマイニングに使ってもよいか?
→(回答)OK - 実際に利用する方法が分かり辛い。
- データをまとめて自動化されたBotプログラムで登録できるのは分かるが、Botは承認を受けるのが難しい(時間がかかる)。手作業で入力するかBotで入れるかの判断は?
- なんでIDが「Q」で始まるの?
→(回答)特に意味はない。初期のWikipedia編集者がQが好きだったから。
また、隣の方が特に熱心にデータを入力しているのを見て、「熱心ですね」と声をかけたところ、「これが将来誰かの役に立つのなら努力を惜しむ理由はないよ」という返答があり、市民参加型の基盤を支えているのは、この考え方だなと思いました。
Exploring the Metadata 2020 outputs
(Metadata 2020の出口を模索する)
昨年はボードゲームでFAIR原則の概念を紹介する独特なセッションを展開していたMetadata2020ですが、今年は議論の場としての開催でした。テーブルごとにチームに分かれ、以下の5件からテーマを選び、チームごとに自由に議論せよというセッションでした。
- メタデータをリッチにした上で、米国のSDGsプロジェクトに合わせていくには、どのように進めていくべきか。
- メタデータをリッチにするためには、実際にどのような活動を実施するべきか?
- メタデータをリッチにするために、どのようなリソースが必要でどのような組織が主導するべきか?
- メタデータをビジネスケースで使う場合、どのようなインセンティブや利益モデルが考えられるか?
- 他
筆者は途中まで参加していましたが、まとめの文書を見る限り、一つのチームあたり5~30件の提案や具体策が示され、とても充実した議論が行われていたようです。
Open Publishing Awards(オープン出版賞授与式)
一日目の日程終了後、「Open Publishing Awards」と題してオープンアクセスやオープンコンテンツに貢献した取り組みを表彰する催しが開催されました。

オープン出版賞授与式の様子
「オープンソースソフトウェア」、「オープンコンテンツ」、「オープンな出版モデル」、「オープン出版への生涯貢献」という四つのカテゴリで、選ばれたコンテンツの代表者が表彰されました。特に市民科学の礎となっている印象があるからか、Wikimedia関連のコンテンツ(Wikidata、Wikijournal)が選ばれた時の歓声が特に大きかったように思います。
二日目以降のセッション
共催のホストであるエディンバラ大学の研究図書館の代表を務めるDominic Tate氏より、「Actionを伴っていきましょう」というWelcomeスピーチで始まり、十数件のセッションとキーノートスピーチに参加しました。この中で印象に残ったセッションについて少し報告します。
Perpetual access machines: archiving web-published scholarship at scale
(永久にアクセスする機械:Web上の学術情報の大規模アーカイビング)
膨大なWebサイトの保存を担っている、米国インターネットアーカイブの方の講演でした。最初に現状のデータ量や構成の報告がなされ、まだデータには無構造な物が多いことが示されました。そして「公共のための」基盤としての今後のロードマップとして、
- オープンな学術情報の収集に力を入れる
- 学術情報へメタデータを自動的に付与するようにする
- オープンなAPI、検索サービスの追加、バルクデータを提供する
- 学術情報のレポジトリであるCrossrefやPubMed、(JST内の)ジャパンリンクセンター、arxiv.orgなどと協力し検索インデックスを取得する
などの活動を続けていくことが示されました。
日本でも国会図書館WARPなどでもWebサイトの保存がなされていますが、それをどのように利用者に提供していくかが今後は重要なポイントになるのかもしれません。
Bringing open scholarship and open education to the public through an academic/public library collaboration
(学術/公共図書館のコラボレーションを通じた、公共へのオープン学術情報とオープン教育の提供)
カナダのゲルフ大学が実施した、研究者と市民科学を志す者のパートナーシップを推進させるプロジェクトの報告でした。このプロジェクトでは大学の研究者と共同研究したい市民を結びつけるために、ゲルフ公共図書館と共同でワークショップを実施したとのこと。図書館の持つデータベースを使いながら、ジャーナルへのアクセスや研究情報へのアクセス方法について講習(資料)を行ったそうです。その際、論文データを手に入れるための法的基準(Sci-HubやTwitterでの著者への論文リクエストなどを行っても良いか)が、あまりよく知られていなかったのが一つの課題となったとのこと。
確かに論文のライセンスは、著者が保有するものや出版社に帰属するものなど様々なものがあり、分かり辛い面があるように思います。本発表のように市民と大学の研究者が手を取り合って研究環境を吟味していくのは一つの切り口となるかもしれません。
Who will influence the success of preprints in biology and to what end?
(誰が生物学のプレプリントの成功に影響を与え、どうなっていくのか?)
このセッションでは、生物系の分野におけるプレプリントサーバの隆盛についてパネルディスカッション形式で議論が行われました。始めにプレプリントサーバ利用の統計について紹介があり、特にbioRχivを使ったライフサイエンス系の論文が急増していること、しかし生命医薬系の論文では2.6%しか利用されていないことが示されました。
それをふまえて、パネリストからは「プレプリントサーバを利用するのは基本的にはオープンサイエンスの推進に繋がるので良いこと」、「医薬系の論文をプレプリントサーバから公開するのは、確定されていない医薬情報が健康被害を出すかもしれないので慎重に」等の意見が出されました。
ポスター発表
本会合でも、NBDCから1件ポスター発表を行いました。NBDC内のサービスがFORCE11の生んだFAIR原則にマッチしていることをアピールし、議論するための情報として公開しました。発表したポスターデータは昨年と同様、CERNの運営するZenodoレポジトリから公開しています。

発表したポスター(写真中央)
終わりに
二日目と三日目は、初日とは数駅離れた場所にある「BT marry field stadium」という競技場が会場でした。折しもラグビーワールドカップ日本大会で日本対スコットランドの試合が行われたばかりのタイミングで、ラグビー選手の練習を横目に見ながらのワークショップは、なかなか気合が入るものとなりました。

会場となった BT marry field stadium(セッションは内部の会議室で行われました)
サイトに登録された参加者は149名。そのうち3名が日本からの参加者でした。前回同様、多くの研究者、図書館員、アーキビスト、出版関係者、ファンディング機関関係者が参加し、活気のあるイベントでした。
次回は2020年10月19~21日にスペインで開催されるそうですので、このような学術環境やデータのオープン化に関する国際的な議論に興味がある方は、ぜひ参加をご検討ください。
著者紹介
大波 純一(おおなみ じゅんいち)
NBDCの横断検索担当。ペットのロシアリクガメと共に堅実なデータアクセス基盤を目指しています。好きな動物:プロングホーン。WikidataのIDはQ63647927。
 Licensed under a Creative Commons 表示4.0国際 license
Licensed under a Creative Commons 表示4.0国際 license
©2020 大波 純一(国立研究開発法人科学技術振興機構バイオサイエンスデータベースセンター)
