データベースを繋いでみよう
¥世界のデータベースが協力して質問に答えてくれたら、素敵じゃないですか?
それが簡単にできると知った時の感動を何とか伝えられれば、とこの記事を書いています。
例えば、食材に含まれるアレルゲンを知りたいとしましょう。
そのために、KNApSAcK DietNavi(註①)という食材のデータベース(食材と生物種の関係が含まれます)と、UniProt(註②)というタンパク質のデータベース(生物種とアレルゲンの関係が含まれます)を使い、食材→生物種(学名)→アレルゲンと繋いでみます(註③)。
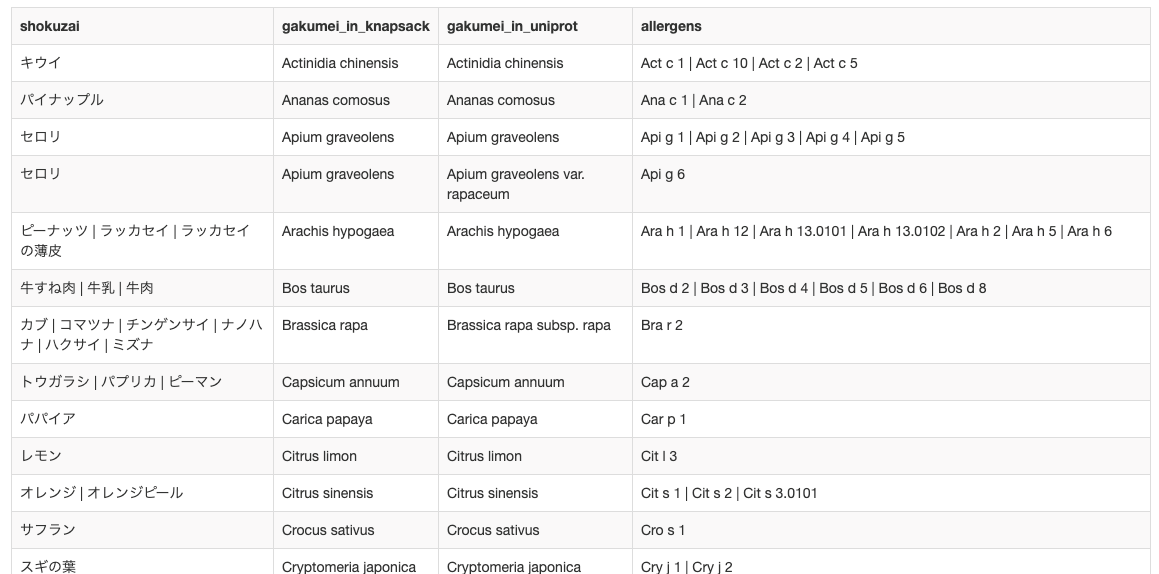
上の画像は下のクエリを、KNApSAcK DietNaviのRDF(註④)が含まれているSPARQLエンドポイント(註⑤)https://dba-rdf.biosciencedbc.jp/sparql(註⑥)に入力して実行した、結果(こちらでご覧になれます)のスナップショットです。
PREFIX up:<http://purl.uniprot.org/core/>
PREFIX ksdn: <http://togodb.biosciencedbc.jp/ontology/knapsack_dietnavi_food#>
SELECT DISTINCT
( GROUP_CONCAT(DISTINCT ?food ; SEPARATOR = " | " ) AS ?shokuzai )
?gakumei AS ?gakumei_in_knapsack
?scientific_name AS ?gakumei_in_uniprot
( GROUP_CONCAT(DISTINCT ?allergen ; separator = " | " ) AS ?allergens )
WHERE {
SERVICE <https://rdfportal.org/sib/sparql> {
?uniprot up:alternativeName / up:allergenName ?allergen .
?uniprot up:organism ?organism .
?organism up:scientificName ?scientific_name .
}
?ks ksdn:gakumei ?gakumei .
FILTER ( STRSTARTS( ?scientific_name , ?gakumei ) || STRSTARTS( ?gakumei , ?scientific_name ) ) .
?ks ksdn:shokuzai ?food .
} group by ?gakumei ?scientific_name order by ?gakumei_in_knapsack ?gakumei_in_uniprot
このクエリの中で、赤字(註⑦)のSERVICE <https://rdfportal.org/sib/sparql> { と } の内側(青字。学名とアレルゲン名を繋ぐ)はUniProtが、外側(緑の字。学名と食材名を繋ぐ)はKNApSAcK DietNaviが受け持ってくれて、協力してクエリに答えてくれています。
このように、SPARQLという言語のSERVICE句を使えば、複数のRDFデータベースを繋ぐことが簡単にできます。
自分のデータを世界のデータと繋ぎたい場合も、Fusekiを使えば驚くほど簡単に繋がりますので、以下の記事などをご参考に試されると良いかと思います。
https://qiita.com/yayamamo/items/0e421cd04636c6bd7359
註
①KNApSAcK DietNaviは、奈良先端大学で提供されているデータベース群KNApSAcK Familyの1つで、病気の予防のためのデータベースですが、ここでは食材と生物種(学名)の関係を得るために用いています。
②UniProtは、タンパク質の巨大な統合データベースです。ここではアレルゲンタンパク質と生物種の関係を得るために用いています。
③学名で繋いだだけですので、右のアレルゲンが左の食材部位に含まれていないことなどがあります。また、エビやカニなどの食材も含めるには、より目的に合うデータを用いる必要があります。
④RDFはResource Description Frameworkの略で、データ形式の一種です。表形式と異なり、トリプルという主語-述語-目的語の小さな単位でデータが表現されています。
⑤SPARQLエンドポイントは、RDFデータを入れたソフトウェア(トリプルストア)の検索窓口で、SPARQLという問い合わせ(クエリ)言語で検索を行うことができます。
⑥このURLは生命科学系データベースアーカイブ(KNApSAcK DietNaviを含む多数のデータベースをダウンロード可能な形で収録)のSPARQLエンドポイントを指しています。表形式のデータを簡易RDF化しています。
⑦このURLはUniProtのSPARQLエンドポイントの代用サイトを指しています。⑥⑦はどなたもお使いになれます。
著者紹介
畠中 秀樹(はたなか ひでき)
NBDC設立時から8年間勤め、この4月にDBCLSに復帰。今もNBDC RDFポータルを担当。10年前までは光合成、タンパク質の立体構造、ウイルス、アレルギーなどを研究。一番好きだったバンドはThe La's。蜜てん(穏健)派。
 Licensed under a Creative Commons 表示4.0国際 license
Licensed under a Creative Commons 表示4.0国際 license
©2019 畠中秀樹(国立研究開発法人科学技術振興機構バイオサイエンスデータベースセンター)
