あなたのデータは「よそ行き」ですか?
生命科学の分野においては、研究過程で産生されたデータを公開リポジトリに登録し、誰もが利用可能にすることが盛んに行われています。古くは核酸・アミノ酸配列やタンパク質構造のデータバンクに始まり、近年では電子顕微鏡画像やマススペクトルなど、より特化したリポジトリも公開されています。
また、論文を掲載するジャーナルにおいても、掲載の条件として論文の関連データをこうしたリポジトリで公開することを要求するケースが増えています。
今やどんなデータであれ、リポジトリで公開することは生命科学の研究者にとってごく当たり前のことになりつつあると言えるでしょう。
こうしたリポジトリで公開されるデータは、研究過程で産生されたデータそのもの(生データ)に対して、その形式を整えたり、メタデータ(データを説明する情報)等を付与したりしたものであるべきです。すなわち、当該研究に関わっていない利用者にとっても、整合性があり、理解しやすいものでなくてはなりません。
いわば、生データやそれに近いデータが「普段着」であるのに対して、公開データは「よそ行き」なのです。
利用者に理解しやすい公開データのために
筆者はNBDCで「生命科学系データベースアーカイブ」 https://dbarchive.biosciencedbc.jp/ (以下、『アーカイブ』)を担当しています。『アーカイブ』では、主に日本の研究者によって産生されたデータセットを収集し、明確なメタデータと利用許諾を付与した上で、ダウンロード可能な状態で公開しています。
『アーカイブ』において収集するデータは本当に多種多様です。「よそ行き」のデータばかりであれば良いのですが、残念ながら「普段着」のままのデータも多く、これらを利用者にとって理解しやすい「よそ行き」に仕立てるために、私たちは日々悪戦苦闘しています。
本稿では、筆者の『アーカイブ』でのデータ加工経験をふまえ、「よそ行き」になっていないデータの事例をいくつか取り上げます。皆様がリポジトリでのデータ公開を考える際に参考にしていただければ幸いです。
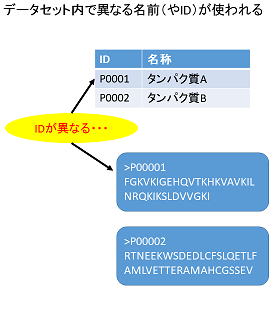
事例1:データセット内で異なる名前やIDが使われている
例えばあるデータセットにおいて、一つのサブセットでは"P0001"のようなIDが使われている一方、もう一つのサブセットでは"P00001"(桁数が1つ多い)のようなIDが使われていることがあります。利用者は、両者が同一かどうか判断に迷います。
やはりIDや名前はデータセットの中で統一すべきでしょう。
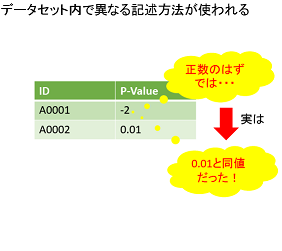
事例2:データセット内で異なる記述方法が使われている
あるデータセットにおいては"-2"と"0.01"が同じデータ項目に入っていました。このデータ項目には負の数は入らないはず、と思って調べたところ、実は"-2"は対数表記であり、"0.01"と同値だったのです!
少し面倒かもしれませんが、記述方法が一貫しているかどうか、確認が必要でしょう。
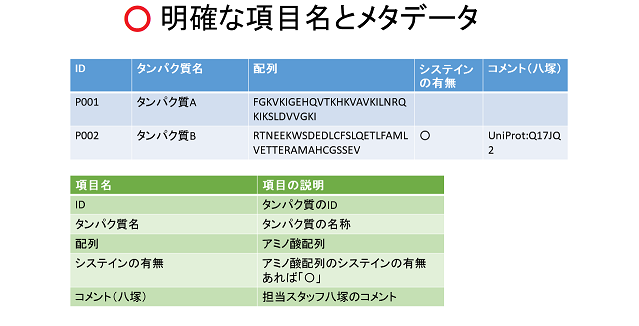
事例3:データ項目が不明確
利用者にとってデータ項目の意味を理解することは非常に重要です。しかしながら、現実には意味不明なデータ項目が多いのです。データの産生者自身や同じ研究室のスタッフにしか通用しない、まさに「普段着」です。
例えば、データ項目名が"col1"、あるいは人名と思しき"yatsuzuka"となっているなど、何を意味しているのか全くわからない極端な例もあります。また、"cysteine"など一見したところ明確に見える名前の項目であっても、それがシステインの何なのかは不明です。略称も2つ以上の意味を持つことが多く、注意が必要です。
もちろんデータ項目名だけで全てを説明することは不可能で、それを説明する情報(メタデータ)が不可欠なのです。逆に言うと、データ項目名は意味不明であっても(仮に"yatsuzuka"であったとしても)、メタデータ(「担当スタッフ八塚のコメント」などの説明)があれば、利用者には理解してもらえるはずです。

事例4:フラグが混入
データの中には、ウェブシステムの中だけで意味を持つフラグ(ウェブページで表示するフォントの色、ある項目の表示・非表示、項目の表示順等)が含まれていることがあります。これらのフラグを含んだままデータを外部のリポジトリなどで公開してしまうと、利用者にはフラグの部分が全く意味不明なものになってしまうのです。
独自システム外にデータを提供する場合は、こうしたフラグはぜひ除去する、あるいはメタデータで説明するようにしましょう。

いかがでしょうか?
上記いずれの場合も、利用者は様々な推測をすることでデータを正しく(?)理解することは可能かもしれません。しかしながら、その推測の正しさを裏付けるためには他のデータを参照したり、データに関連する論文等を調べたり、場合によっては既に運用停止したデータ提供元のサイトをウェブアーカイブで調査したりなど(これらは私たちの『アーカイブ』で実際に行っていることです)、筆者が「データ探偵」と呼んでいる一連の調査が必要になってしまいます。
もちろん、データの整理やメタデータの付与といった作業は面倒でしょう。特にデータ量が多ければなおさらです。しかし、データを「よそ行き」に仕立てることはデータの価値、ひいては研究自体の価値を高めることにつながると筆者は信じています。
それでも「データの整理方法がよくわからない」「忙しくてデータの整理まで手が回らない」という方も多いと思います。そのような場合は、ぜひ『アーカイブ』へのデータ寄託 をご検討ください。皆様のデータを「よそ行き」に仕立てるお手伝いをさせていただきます。
 Licensed under a Creative Commons 表示4.0国際 license
Licensed under a Creative Commons 表示4.0国際 license
©2018 八塚茂(国立研究開発法人科学技術振興機構バイオサイエンスデータベースセンター)
