第3回「植物ゲノムデータベースの統合」
はじめに:我が国の植物ゲノム研究
我が国の植物ゲノム研究は,1986年に世界にさきがけて行われた,名古屋大学グループによるタバコ葉緑体の全ゲノムの塩基配列決定,および,京都大学グ ループによるゼニゴケ葉緑体の全ゲノムの塩基配列決定により黎明期をむかえたといえよう.そののち,1996年にかずさDNA研究所により光合成を行う生物として世界で初めてシアノバクテリアの全ゲノム構造が明らかにされ[1], さらに,2004年には東京大学グループにより単細胞紅藻として初めてシアニディオシゾンの全ゲノム構造が決定された.一方,高等植物においては,2000年に完了したシロイヌナズナゲノム解読国際プロジェクトにより植物として初めて全ゲノム構造が決定されたが,ここではかずさDNA研究所が大きな役割をはたした.また,農林水産省の主導で進められたイネゲノム解読国際プロジェクトは2004年に終了し,主要作物の全ゲノム構造が初めて解明された[2].これらにくわえ,単細胞緑藻クラミドモナス,ヒメツリガネゴケ,コムギ,オオムギなどのゲノムやcDNAの構造解析,大規模な遺伝子機能の解析の分野において我が国が大きな貢献をした例は枚挙に暇がない.
動物のゲノム研究は,進化系統上における特徴を考慮しつつもつねに頂点としてヒトを意識しながら進められる.一方,植物のゲノム研究においては,産業における重要性から穀類,野菜,果樹,樹木,花など多種多様な植物が対象となる[3]. しかし,長年の選抜により育成された産業植物は複雑で大きなゲノムをもつものが多いことから,ゲノム研究の対象とはなりにくい.そのため,まず少数の実験植物について集中的にゲノムの構造や機能の研究が進みつつも,つねに多様な産業植物への展開が意識されてきた.しかしながら,次世代シークエンサーに象徴されるゲノム解析機器や情報解析技術のここ数年の急速な進歩と普及により,その障害は取り除かれつつある[4].
我が国でも,この流れをうけて基礎・応用を問わず幅広い研究の材料となるさまざまな植物種がゲノム解析の対象になりつつある.その結果,ゲノム塩基配 列,cDNA塩基配列,転写産物の量,ゲノムにおける番地ともいえるDNAマーカー,これを用いて構築される高精度なゲノムの遺伝的な連鎖地図,ゲノムDNAライブラリーなど,さまざまなゲノム関連情報やリソースが整備され,これらを利用することよりゲノム進化,有用遺伝子の同定と単離,分子育種など幅広い研究分野の活性化が起こっている.さらに,周辺技術の進歩をうけてタンパク質,タンパク質修飾,代謝産物,表現型などの大規模な解析が行われ,これに関連する大量のデータが蓄積しつつある[5].
1.植物ゲノムデータベースの現状と問題点
DNA塩基配列データは,論文の発表の際に国際DNAデータベース(我が国では日本DNAデータバンク:DDBJ,URL:http://www.ddbj.nig.ac.jp/)にあらかじめ登録し,データベースをつうじ公開することが義務づけられている[6]. しかし,国際DNAデータベースは基本的に塩基配列データのレポジトリー(保存場所)であり,塩基配列,予測遺伝子の領域や機能など,かぎられた情報しか登録できない.そのため,連鎖地図,転写,翻訳,代謝産物,形質,DNAマーカーなど,高次で多様な情報はWebに個別に構築されたデータベースをとおして,ユーザーが見やすく使いやすいかたちで公開されることが多い[7].実際,国内には現時点で190をこえる植物ゲノム関連のデータベースが存在し,幅広い植物種から得られたさまざまなゲノム関連情報が提供されている(表1). 任意の生物種についてゲノム関連情報を入手しようとするユーザーは,まず,国際DNAデータベースを検索してどのような生物種のゲノム情報が登録されているかを調べ,もし登録されていれば必要な情報をダウンロードする.つぎに,個別のデータベースにアクセスしてどのような情報が公開されているかを調べて利用することになる.
ゲノムデータベースを利用する際にユーザーがもっともとまどう点は,どこにどのようなデータベースが公開されているのかを容易に把握できないことであろう.データベースは,ゲノム解析を行なった研究グループ単位,研究プロジェクト単位,さらには,同一のグループでも生物種単位,データの種類(塩基配列, 形質,そのほか)単位などで,収集したデータを整理し当面公開することを目的として構築されることが多い.そのため,同一の生物種に由来し,しかも,さまざまな種類のゲノム関連データを格納したデータベースが国内外に散在する結果となり,それらの存在や内容をすべて把握することは不可能といってもよい.そして,個々のデータベースが提供するデータはほかのデータベースのデータとは独立であるため,ユーザーは原則として関連するデータベースすべてを検索しなくてはならない.さらに,それぞれのデータベースは異なるスタイルで作成されているため使い方がまちまちであることも問題といえよう.海外の研究者が我が 国の植物ゲノムデータベースを利用しようとする際にはこの問題はより深刻で,有用な情報が大量に提供されているにもかかわらず十分には活用されず,我が国の植物ゲノム研究のプレゼンスが示されないという状況になっている.今後,ゲノム解析技術がより普及し対象となる植物が多様化することにより,さらに多数のデータベースが乱立することが予想される.そのため,データベースを統合しユーザーの利便性を高めることは喫緊の課題といえる.
2.植物ゲノムデータベースの統合
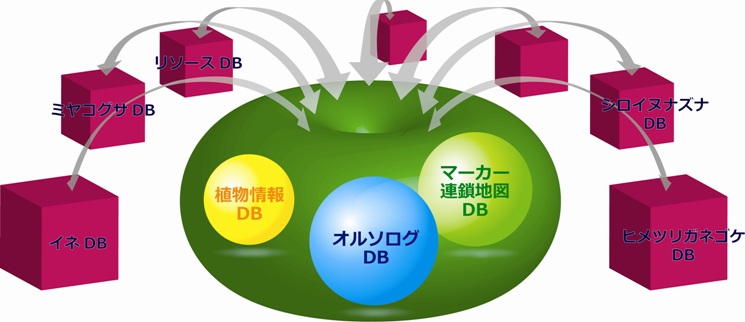
このような課題を解決するため,国内の植物ゲノムデータベースを統合する試みがはじまっている.統合の方法として,すべてのデータベースに格納されている 全データを一箇所に集め共通のフォーマットにて提供することがもっとも望ましいが,技術あるいは制度における問題から現実的な選択肢ではない.そのため, 現存するデータベースの特徴を活かしつつ,散在するデータがあたかもひとつのデータベースから提供されているようなしくみをつくることが求められている. そこで,多数のデータベースを統合するためのキーとなる方法として,遺伝子のオルソログ(共通起源の単一の遺伝子から種の分化により生じた相同性をもつ遺伝子)の関係を利用することが考えられた[8]. さきにも述べたように,データベースから公開されている遺伝子の塩基配列は,原則としてすべて国際DNAデータベースにおいて登録・公開されている.そこで,まず,国際DNAデータベースから植物に由来するすべての遺伝子配列データを取得し,塩基配列から翻訳したアミノ酸配列を総当たりで相同性検索して, 生物種のあいだの進化系統の関係を反映させた階層的な遺伝子オルソログデータベースを構築する.そして,多数のデータベースにある対応する遺伝子の関連データに外部から認識できるようなタグをつけ,ここで得られた階層的なオルソログの関係にもとづいて木構造状に相互リンクする.これにより,遺伝子の機能や分類の階層構造を反映させたかたちで,国内に散在する植物ゲノムデータベースを遺伝子レベルで関連づけ統一的に閲覧することが可能となる.
遺伝子情報のほかの情報についてもデータベースの統合が進んでいる.遺伝子情報とならんで重要なゲノム情報としてDNAマーカーや遺伝的な連鎖地図があげられる[9].これらは遺伝解析による有用遺伝子の同定やゲノム構造の比較に必須であるのみならず,マーカー選抜育種やDNA鑑定など応用研究や産業における価値も高い[10].DNA マーカーの一部はマーカー周辺の塩基配列により相互にリンクすることができるが,文献のみで公開されているものも多いことから,文献情報の収集とデータベース化を並行して行うことが必要である.これにくわえて,国内に散在する植物バイオリソース(種子,変異体,cDNAやゲノムDNAのクローンなど)の情報を統合的に検索可能とすること,つぎつぎに全ゲノムの解読が完了する多様な植物について,分類,植物形態,植物生理,植物地理,生態といった基本知識や,農学,園芸学,育種学的な情報,さらには,ゲノム解析の手法まで記載・解説した総合情報データベースを構築すること,植物オミクス情報などゲノム機能情報に関連するデータベースを調査しリンク情報を整理することによりデータベースを横断的に検索する機能を備えたポータルサイトを構築すること,なども計画されている.
おわりに
ゲノム解析技術の進歩と普及にともない,植物ゲノム関連データベースの対象となる生物種や内容は急速に増加しつつある.また,データベースに対するユー ザーの要望も多様化している.この変化に対応してユーザーの利便性を確保することは容易ではないが,データベース統合化の努力が実を結べば,国内に存在す るゲノム情報および周辺情報が有機的に統合され情報探索の利便性が高まる(図1).その結果,ゲノム関連研究がより効率化するとともに,我が国の植物ゲノム関連の研究成果が海外から"目に見える"かたちとなることが期待されている.
参考文献
- 榊 佳之, 金久 実, 中村祐輔, 大木 操, 小原雄治, 高木利久 編: ゲノムサイエンス:生命の全体像の解明をめざして. 共立出版 (1997) ↑
- International Rice Genome Sequencing Project: The map-based sequence of the rice genome. Nature, 436, 793-800 (2005) ↑
- 鵜飼保雄, 大澤 良 編著: 品種改良の世界史:作物編. 悠書館 (2010) ↑
- 榊 佳之, 伊藤隆司, 辻 省次, 小原雄治 編: ゲノム情報と生命現象の統合的理解2007. 羊土社 (2007) ↑
- 森下真一, 阿久津達也 編: バイオデータベースとソフトウェア最前線. 羊土社 (2008) ↑
- David W. Mount著, 岡崎康司, 坊農秀雅 監訳: バイオインフォマティクス 第2版. メディカル・サイエンス・インターナショナル (2005) ↑
- ナショナルバイオリソースプロジェクト情報運営委員会 監修: バイオリソース&データベース活用術. 秀潤社 (2009) ↑
- T. A. Brown著, 村松正實, 木南 凌 監訳: ゲノム 第3版. メディカル・サイエンス・インターナショナル (2007) ↑
- 西尾 剛 編: 遺伝学の基礎. 朝倉書店 (2006) ↑
- 鵜飼保雄: 植物育種学. 東京大学出版会 (2003) ↑
↑ 押下で本文に戻ります。
表説明
表1 国内の主要な植物ゲノムデータベース(2011年9月現在)
| 対象植物 | データベース名 | 主な提供情報 | URL | 公開機関 |
|---|---|---|---|---|
| シロイヌナズナ | RIKEN Arabidopsis Genome Encyclopedia (RARGE) | 完全長cDNA、マイクロアレイ、転写因子、その他 | http://rarge.psc.riken.jp/ | 理化学研究所 |
| イネ | Oryzabase | リソース、cDNA、地図情報(連鎖、物理、比較)、その他 | http://www.shigen.nig.ac.jp/rice/oryzabase/top/top.jsp | 国立遺伝学研究所 |
| コムギ | KOMUGI | リソース、cDNA、マーカー、連鎖地図、その他 | http://www.shigen.nig.ac.jp/wheat/komugi | 京都大学、NBRP* |
| オオムギ | BARLEY DB | cDNA、EST、ゲノム、 連鎖地図 |
http://www.shigen.nig.ac.jp/barley | 岡山大学、NBRP |
| トマト | ナショナルバイオリソースプロジェクト トマト | リソース | http://tomato.nbrp.jp/ | 筑波大学、NBRP |
| イネ | Rice Annotation Project Database (RAP-DB) | アノテーション | http://rapdb.dna.affrc.go.jp/ | 農業生物資源研究所 |
| コムギ、オオムギ | TriFLDB: Triticeae Full-Length CDS DataBase | 完全長cDNA | http://trifldb.psc.riken.jp/index.pl | 理化学研究所 |
| ミヤコグサ、ダイズ、 タルウマゴヤシ |
LegumeTFDB | 転写因子 | http://legumetfdb.psc.riken.jp/ | 理化学研究所 |
| ミヤコグサ、ダイズ | Legume Base | リソース | http://www.legumebase.brc.miyazaki-u.ac.jp/index.jsp | 宮崎大学、NBRP |
| ミヤコグサ | miyakogusa.jp | ゲノム配列 | http://www.kazusa.or.jp/lotus/index.html | かずさDNA研究所 |
| ダイズ | SOYBEAN PROTEOME DATABASE | プロテオーム | http://proteome.dc.affrc.go.jp/Soybean/ | 作物研究所 |
| アズキ | アズキ・ケツルアズキのSSRマーカー情報 | 連鎖地図、マーカー | http://www.gene.affrc.go.jp/databases-marker_information.php | 農業生物資源研究所 |
| ラッカセイ | Peanut Marker Database | マーカー | http://marker.kazusa.or.jp/Peanut/ | かずさDNA研究所 |
| クローバー | Clover Garden | 連鎖地図、マーカー | http://clovergarden.jp/ | かずさDNA研究所 |
| ナス、ハクサイ、ネギ、キュウリ、メロン、トマト | VegMarks | 連鎖地図、マーカー | http://vegmarks.nivot.affrc.go.jp/VegMarks/jsp/index_j.jsp | 野菜茶業研究所 |
| ダイコン | Daikon Marker Database | マーカー | http://marker.kazusa.or.jp/Daikon/ | かずさDNA研究所 |
| キャッサバ | Cassava Full-Length cDNA Database | 完全長cDNA | http://amber.gsc.riken.jp/cassava/index.php?contents=to | 理化学研究所 |
| ヤトロファ | Jatropha Genome DataBase | ゲノム配列 | http://www.kazusa.or.jp/jatropha/ | かずさDNA研究所 |
| キク属 | ナショナルバイオリソースプロジェクト 広義キク属 | リソース、マーカー | http://www.shigen.nig.ac.jp/chrysanthemum/index.jsp | 広島大学、NBRP |
| アサガオ | ナショナルバイオリソースプロジェクト アサガオ | リソース、マーカー | http://mg.biology.kyushu-u.ac.jp | 九州大学、NBRP |
| スギ、ヒノキ | スギゲノムデータベース | 連鎖地図、マーカー、cDNA | http://www.ffpri.affrc.go.jp/labs/cjgenome/indexj.html | 森林総合研究所 |
| ポプラ | RPOPDB: RIKEN Populus Database | ゲノム配列 | http://rpop.psc.riken.jp/index.pl | 理化学研究所 |
| コケ | PHYSCObase | EST | http://moss.nibb.ac.jp/ | 基礎生物学研究所 |
| 藻類 | Algae Resource Database | リソース | http://www.shigen.nig.ac.jp/algae/ | 国立環境研究所 |
| クラミドモナス | Chlamydomonas reinhardtii EST Index | EST | http://est.kazusa.or.jp/en/plant/chlamy/EST/index.html | かずさDNA研究所 |
| スサビノリ | Porphyra yezoensis EST Index | EST | http://est.kazusa.or.jp/en/plant/porphyra/EST/index.html | かずさDNA研究所 |
*NBRP:National BioResource Project

Licensed under a Creative Commons 表示2.1日本 license ©2012 田畑哲之(かずさDNA研究所)
なお、本記事は細胞工学2011年12月号掲載の原稿を改変したものです。
